
altair의 프로젝트 일기
Diary 프로젝트 일기 (3) 본문
회고
취준과 공부, 개발을 동시에 하려니 생각보다 셋 다 속도가 나지 않았다. 그래도 이제는 프로젝트의 개발의 패턴이 어느 정도 자리잡아 간다고 느낀다. 기술 스택과 CI/CD 파이프라인 등이 정해지니 이제 비로소 개발 본질에 집중하게 된 듯하다. 이번 글에서는 지금까지 어떤 진전이 있었고 어떤 문제와 해결이 있었는지 적어보려한다.
프론트엔드 - 디자인 반영
가장 눈에 띄는 변화는 드디어 프론트엔드 디자인의 대부분이 반영되었다는 점이다. 다음은 디자인 가이드와 실제 웹 페이지다.

몇몇 수정 외에는 거의 디자인 가이드를 따라가보았다. 사실 보고 그대로 만들기만 하면 되는 건데 뭐가 대단하냐 할 지 모르겠다. 그렇지만 이전까지 바닐라JS만 겨우 끄적대봤던 나이기에 NextJS를 통해서긴 하지만 처음으로 리엑트를 써서 구현한거라 뿌듯했다. 특히 useEffect를 위시한 랜더링 과정과 백엔드와의 비동기 요청 처리, 특히 전역적 로그인 상태 관리 같은 이슈를 다룰 때는 포기해야 하나 싶기까지 했다. zutsand 같은 상태 관리 라이브러리와 swr를 사용해 대강 원하는 기능들을 만들었고 프론트엔드와 JS의 비동기 패러다임은 생각보다 익히기 어려웠다. 사실 아직도 '안다'고 하기에는 부족하지 않나 싶다.
그래도 이제 토큰 재발급을 포함한 기본적인 JWT 로그인 처리, 댓글과 대댓글 시스템, 유저 별 단 한 번만 가능한 좋아요 기능 등, 가장 중요하다고 생각했던 기능들은 구현하였다. 비록 완전히 체화되지는 않았지만, 그리고 많은 시간이 걸렸지만, 리엑트로 이런 컴포넌트들을 유지보수 가능하도록 만들었다는 사실은 나름 뿌듯한 성공이다.
백엔드 - 테스트 커버리지
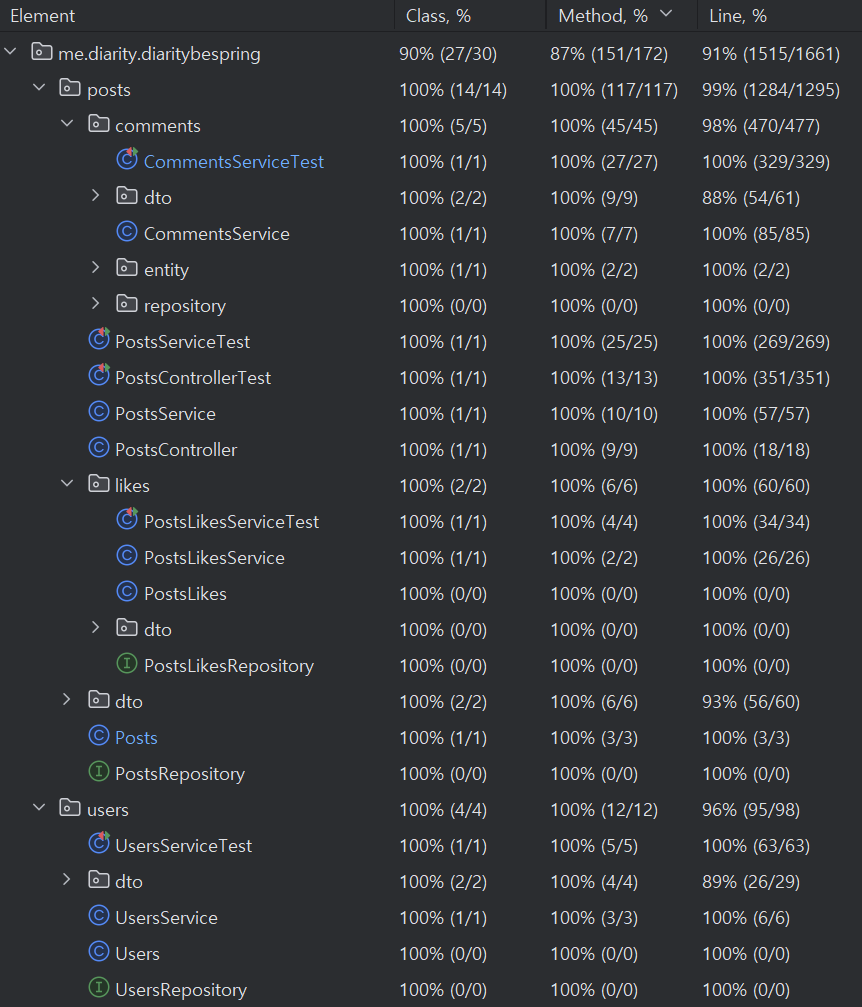
가장 중요한 비즈니스 로직인 게시글과 유저 관리 기능의 테스트코드는 메서드 단위에서 모두 100%의 커버리지를 달성했다. 특히 중요한 로직들은 실패 테스트 또한 작성하여 훨씬 촘촘하고 믿을 수 있는 코드를 만든 것 같아 뿌듯했다.
물론 유닛 테스트가 전체 시스템의 신뢰성을 보장하지는 않는다. 그럼에도 불구하고 예를 들어 내가 원하는 댓글 데이터가 프론트에 떨어지지 않을 때, 내 백엔드 로직에는 이상이 없을 것이라고 상대적으로 강하게 보장할 수 있는 근거가 생겨, 프론트엔드를 만들 때 중요한 앵커로 기능했음은 말할 필요도 없을 것이다. 더욱이 지금처럼 여러 단계를 거쳐 원격 서버에 배포하는 경우, 문제가 생겼을 때 그 이유가 JAR 내부에 있지 않다는 것을 확신할 수 있기에 인프라 구성에서도 매우 유용한 개발이었다고 생각한다.
문제는 테스트 작성 자체가 굉장한 수고를 필요로 한다는 것이다. 심지어 AI의 도움을 풀로 땡겼음에도 굉장히 귀찮았다. 포스트를 작성하는 서비스의 메서드를 테스트한다고 해보자. 이미 존재하는 유저인지 검증한 후 바로 레포지토리에 포스트를 저장하기만 하면 된다. 하지만 테스트 코드는 훨씬 많아진다. 존재하는 유저의 요청일 경우, 존재하지 않는 유저의 요청일 경우 이렇게 두 개로 나눠진다. 로직이 복잡해질수록 그 모든 브랜치의 실패를 모두 테스트해야 한다.
심지어 비즈니스 로직이 바뀔 경우 테스트도 수정해야 한다. 포스트 전체를 불러오는 로직은 꽤나 복잡한데, 익명 유저일 경우, 로그인 유저일 경우, 또 로그인 유저일 경우 각각에 대해 좋아요를 누른 포스트와 아닌 포스트를 따로 설정해 반환해야 한다. 이 모든 분기에 대해 테스트를 하고 있는데, 만약 이 메서드의 반환 DTO 클래스가 바뀐다면? 파라미터가 바뀐다면? 심지어 테스트 자체도 언제나 리팩도링 대상이다. 반복되는 객체 생성의 경우 어떻게 함수로 바꿀 것인가? 반복되는 assert문은 어떻게 하나로 합칠 것인가?
때문에 본 서비스의 로직보다 테스트에 너무 많은 공을 들인게 아닌가 싶다. 왜 소프트웨어 마에스트로 멘토님이 서비스 초기에 커버리지 테스트보다 전체 API 테스트를 더 권장하셨는지 알 것 같다. 빠르게 개발하는게 더 중요한게 아닌가 이제와서 생각해본다.
인프라
원래 무료 도메인 서비스인 duckdns를 사용해 젠킨스와 Harbor에 접속해왔었다. 그런데 어느 날부터 duckdns에 연결된 모든 서비스가 DNS 오류로 서버를 찾지 못하는 것이 아닌가? 내부 ip로 접속하면 문제 없이 들어가지는걸 봐서는 duckdns 쪽에서 뭔가 이슈가 있는 듯 했다. 이 현상이 사라지지 않아서 결국 가비아에서 도메인을 샀다. cloudflare로 네임서버를 옮기고, 리버스 프록시에서 와일드카드 인증서를 적용했다. 역시 돈내고 쓰는 서비스는 이유가 있는 법이다.
문제는 Harbor 도메인을 바꾸면서 젠킨스의 배포 스크립트를 수정하지 않아서 배포가 제대로 되지 않았었다. 로컬에서 ssh로 연결해 배포하는데 이 ssh 스크립트의 실행 결과를 젠킨스에서 문제삼지 않고 무조건 성공이라고 전달해버린 것이 문제였다. 백엔드에서 전달하는 쿠키의 옵션들이 개발 서버에 제대로 반영되지 않는 것이 발단이었는데, 아무래도 쿠키 관련 문제였기에 리버스 프록시 보안 설정이 문제인줄 알고 한참을 뻘짓한 탓이 컸다. 점점 단순한 ssh 배포가 한계에 도달하는게 아닌가 싶다.
이런 트러블슈팅을 할 때마다 우리가 얼마나 깨지기 쉬운 시스템을 갖고 있는지 느낀다. 특히 홈서버에서 온프로미스로 직접 배포하면 더욱 많은 Single Point of Failure가 있는지 알게된다. 이렇게 도메인만 바뀌어도 전체 배포 과정이 무너지고, 배포 대상 서버의 ip가 바뀌어도 무너진다. 당연히 DB는 단일 인스턴스이기 때문에 여전히 자유롭지 않고, 스키마는 매 배포마다 위협받는다.
쿠버네티스니 테라폼이니 이런거까지 알아야하나 싶은 기술들이 사실은 다 불완전한 시스템을 어떻게든 완전하게 만들고 싶어서 생긴 것은 아닐까 생각해본다.
'IT > 서버' 카테고리의 다른 글
| Diary 프로젝트 일기 (2) - CI/CD 파이프라인 (0) | 2025.02.26 |
|---|---|
| [소프트웨어 마에스트로] 단어 가중치 서버 제작기(feat. TF-IDF) (0) | 2025.01.01 |
| 알리에서 산 컴퓨터로 나만의 라우터 만들기 (0) | 2024.08.19 |
| AWS Multipart 파일 업로드 시 403 오류 해결 (0) | 2024.07.26 |
| 홈서버 변화사 (0) | 2023.11.09 |



