
altair의 프로젝트 일기
[소프트웨어 마에스트로] 단어 가중치 서버 제작기(feat. TF-IDF) 본문
개요
소프트웨어 마에스트로 과정에서 개발한 서비스가 단어마다 중요도를 매기는 서버를 필요로 했다. 우리의 백엔드는 스프링부트 웹서버와 단어 가중치 서버로 구성된다. 스프링 서버는 입력 받은 페이지의 단어들을 분석하기 위해 단어 가중치 서버에게 단어들의 중요도를 부여해달라고 요청한다. 이번 글에서는 더 늦어 잊어버리기 전에 해당 서버를 어떤 방식으로 구축하고 서버가 어떤 방식으로 단어들의 중요도를 평가하는지 설명해보려 한다.
문제
우리가 만든 서비스 빈채는 학생들을 위한 빈칸 자동 생성 서비스이다. 학생들이 개념서 페이지를 찍어 올리면 거기에 있는 단어들을 분석해 외워야 할 단어들에 빈칸을 치는 방식이다. 그렇기 때문에 OCR을 처리하는 기능과 단어 목록을 받아 각 단어들의 중요도를 평가하는 기능이 필요하다. OCR은 네이버 클로바 OCR API를 돈주고 사용하기로 했다. 단어 가중치 평가 기능은 따로 구현된 바가 없어 우리가 직접 구현해 써야했다.
사실 그때 우리의 규모를 생각하면 스프링 서버에서 모든 걸 처리해도 문제 없었다. 당연하다. DAU가 없으니. 그렇지만 따로 파이썬 서버를 만들기로 한 이유가 있었다.
- 이미 단어 가중치 서버를 POC와 프로토타입을 위해 파이썬으로 구축해보았었다. 해당 서버는 ChatGPT API를 사용해 가중치를 반환했다.
- 우리의 유스케이스에서 가장 사용하기 쉽고, 빠르고, 정확한 형태소 분석기인 khaiii(카카오 한국어 형태소 분석기)가 파이썬으로 기본 제공되고 있었다.
먼저 형태소 분석기에 대한 이야기를 해보자.
형태소 분석기
한국어 단어의 가중치를 평가하기 위해서는 단어들을 형태소라는 단위로 분리할 필요가 있었다. 형태소는 단어를 더 이상 분리할 수 없는 단계까지 분리한 결과를 말한다.
예를 들어, '아름답다'를 형태소로 분리하면 형용사인 '아름답'과 종결 어미인 '다'로 분리할 수 있다. 마찬가지로 '아름다운'을 분리해보면 형용사인 '아름답'과 관형형 전성 어미인 'ㄴ'으로 분리할 수 있다. 여기서 중요한 점은, 한국어와 같이 같은 의미를 가진 단어가 위치에 따라 그 형태가 변할 경우에도 형태소 분리를 사용하면 비록 형태가 달라도 어떤 의미를 가지고 있는지 훨씬 분명하게 알 수 있다는 것이다. '아름답다'와 '아름다운'을 단순한 문자열로 처리하면 둘은 다른 의미를 가진 단어가 된다. 형태가 다르기 때문이다. 하지만 형태소 분석을 한 다음에는 두 단어의 의미를 갖는 형태소가 '아름답'이므로 두 단어는 같은 의미를 가진 단어로 판단할 수 있다. 이 점이 형태소 분석을 하는 이유이다.
형태소 분석의 경우 연구 성과가 이미 몇 년 전에 대부분 개발 완료되었다. 그 개발 결과물 중에서 우리는 카카오의 형태소 분석기 khaiii를 사용하기로 했다. 다음과 같은 이유가 있었다.
- 내게 익숙한 우분투에서 파이썬 패키지를 빌드 및 설치할 수 있도록 문서를 제공하고 있었다. 그래도 우분투 22에 설치하기 위해서는 조금 수정이 필요하다.
- 우리가 테스트한 형태소 분석기 중에서 가장 설치하기 쉬웠고, 빨랐고, 정확했다. 그리고 무엇보다 형태소 분석기 중에서는 제일 최신 연구결과를 반영한 상태였다.
분석기를 설치한 인스턴스를 템플릿으로 만들어 블루-그린 CICD 파이프라인에서 사용할 수 있었다.
가중치 계산
가중치 계산 방법을 구현하기 전에 각 방법이 올바른 방향으로 의미있는 결과를 도출하는지 확인할 테스트 환경이 필요했다. 우리의 서비스는 (1)중고등학생들을 위한 서비스이고, (2)암기 위주 과목에 최적화된 서비스이며, (3)빠른 테스트를 위해서는 키워드를 확보하기 쉬운 과목을 선정해야 했다. 따라서 고등학교 수능특강 한국사 1단원의 개념부분 첫 페이지를 테스트 기준으로 삼았다. 만약 시간적 여유가 더 많았다면 다양한 테스트셋을 확보했겠지만, 우리의 목표가 가중치 서버의 정확도 향상이 아닌 빠른 서비스 출시이기 때문에 그러지 않았다.
Ideal한 목표는 해당 페이지에 직접 우리가 빈칸을 만든 결과로 설정하였다.
가중치 계산은 두 부분으로 구성하였다. 하나는 과목별 딕셔너리 탐색, 하나는 TF-IDF이다. 먼저 딕셔너리 방식부터 살펴보자.
딕셔너리 방식
초기 POC단계에서 사용한 방식인데, 가장 먼저 떠오른 방식이기도 하고 구현하기 쉬운 방식이기도 한 딕셔너리 탐색이다. 미리 개발자가 저장해놓은 (단어: 가중치) 쌍을 탐색해 현재 단어가 존재하는지, 존재한다면 어떤 가중치로 설정되어 있는지 탐색하는 방식이다.
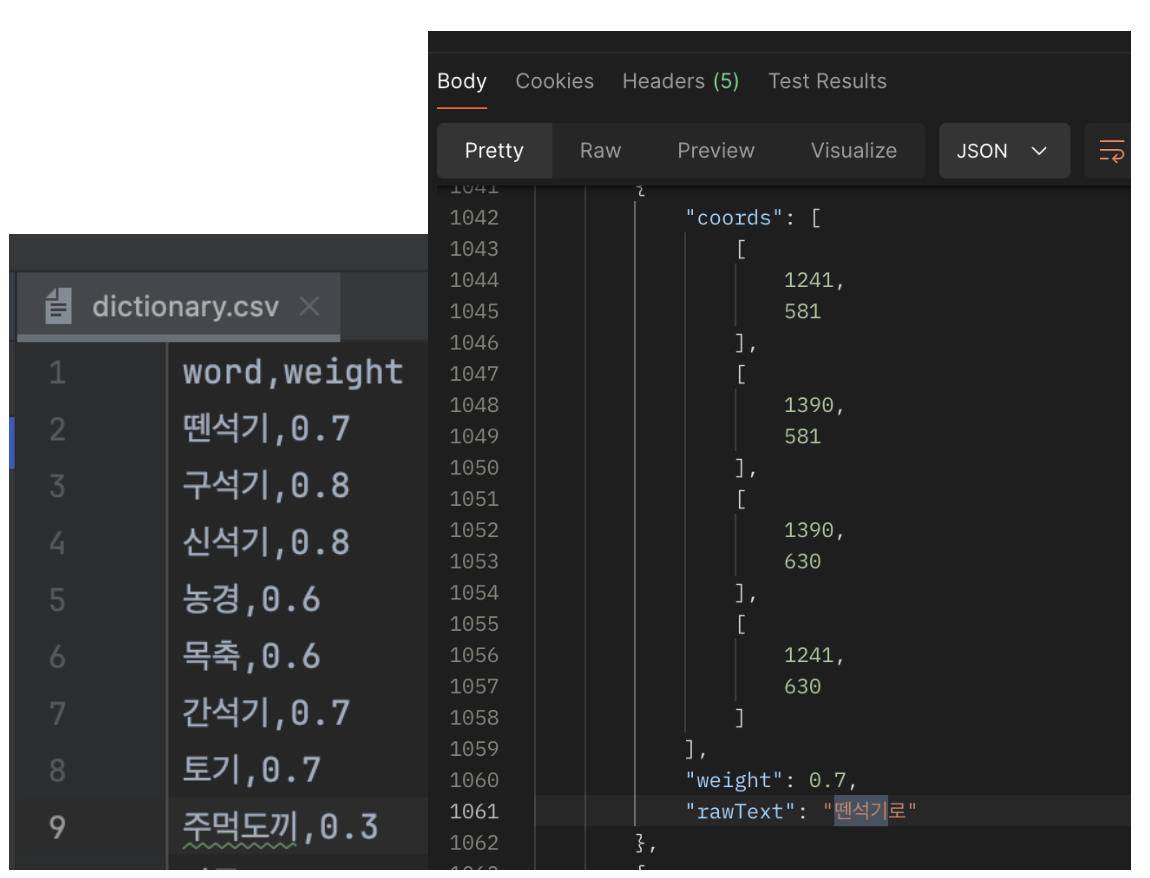
초기 MVP는 csv 파일에 왼쪽처럼 각 쌍을 저장했다. 실제 테스트셋 요청의 응답을 확인해보면 "뗀석기로"라는 토큰의 가중치가 미리 설정된 0.7로 나온 것을 볼 수 있다.
그러나 이 방법은 문제가 있는데 입력값의 범위가 작다면 아주 간단하고 효율적이지만 입력값의 범위가 현행교육과정처럼 넓다면 그에 해당하는 모든 키워드를 미리 확보해야 할 뿐만 아니라 각각의 가중치가 자의적으로 저장된다는 치명적인 단점이 존재한다. 따라서 더욱 일반적으로 사용할 수 있는 방법이 필요했다.
그 방법을 우리는 TF-IDF에서 찾았다.
TF-IDF
TF-IDF는 입력 문자열에서 의미있는 토큰을 분리해내는 방식이라고 할 수 있다. 더욱 정확히는 문자열의 토큰들에 점수를 매긴다.

TF-IDF의 TF값과 IDF값은 각각 위와 같다. 조금 더 풀어서 설명하면 다음과 같다.

현재 문서에서 해당 단어가 등장하는 빈도가 TF이고, 해당 단어가 등장하는 다른 문서의 개수에 역수를 취한 값이 IDF이다. 즉, 현재 문서에서 많이 나올수록, 다른 문서에서 나오지 않을수록 단어의 점수가 증가하는 것이다. 이러한 방식으로 초기 MVP 개발에서는 단어들의 중요도를 기초적으로나마 계산할 수 있었다.
결과
먼저 테스트 결과부터 보자.
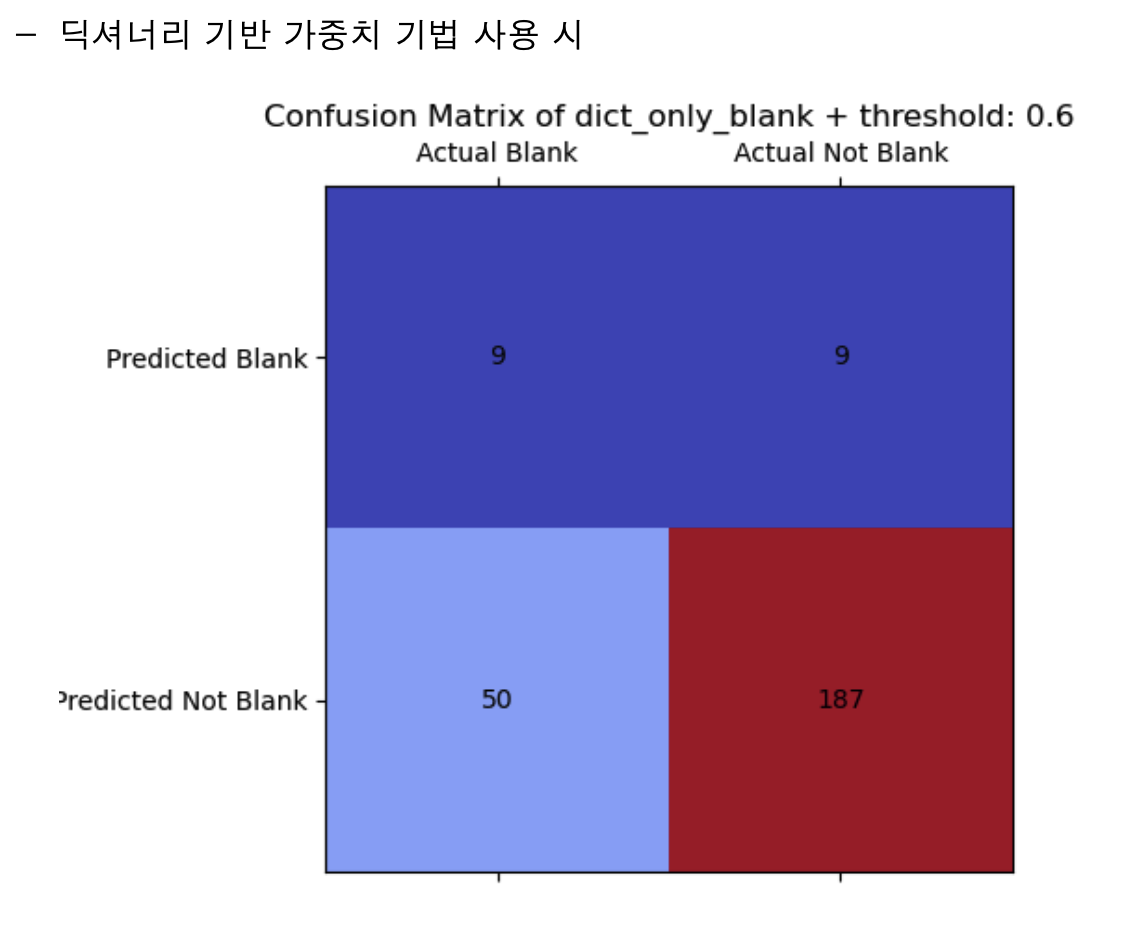
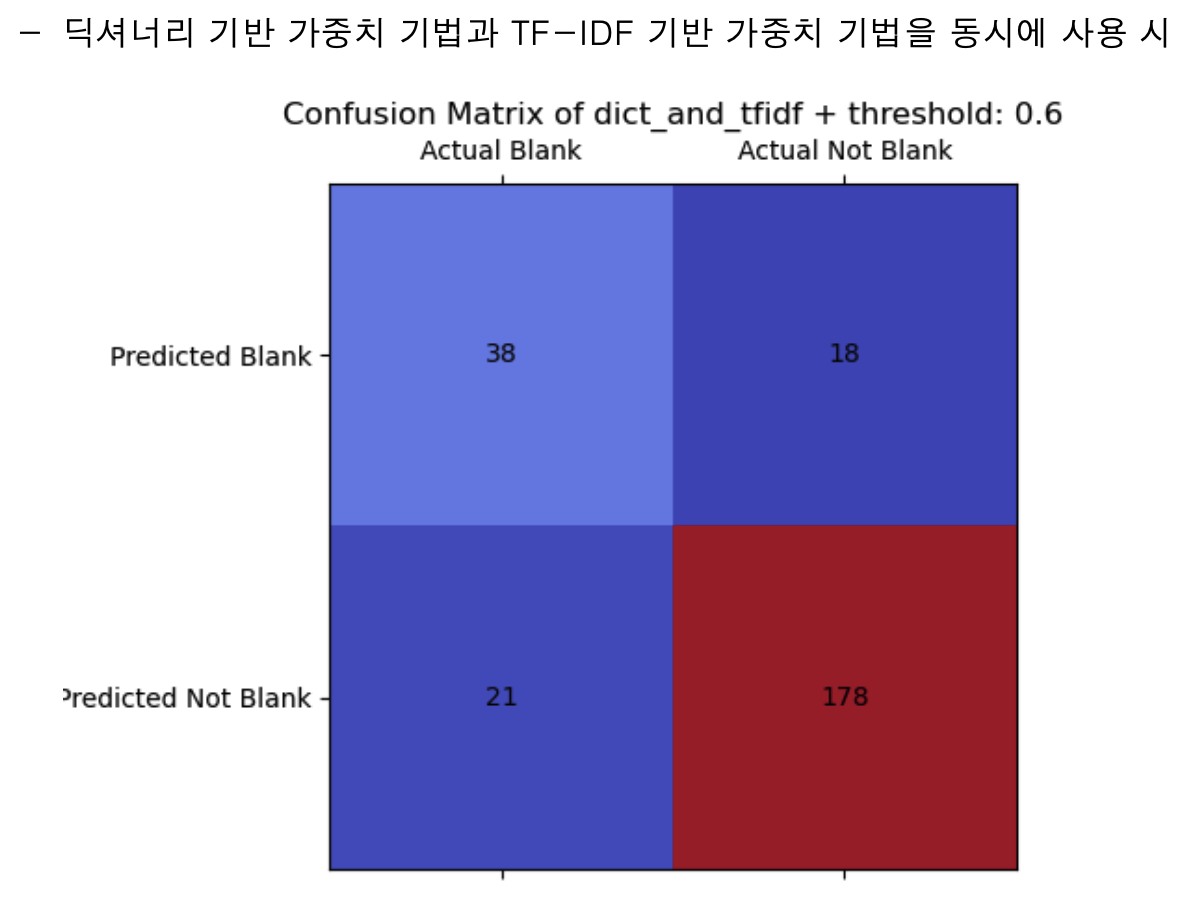
결과에서 보다시피 순수한 딕셔너리 방식은 명확히 좋지 않은 적중률을 보인다. 그에 비해 TF-IDF 값을 더한 결과는 조금 더 나은 모습을 보인다. 실제 다양한 개념 페이지에 적용했을 때도 생각보다 어느 정도 적중률을 확보한 모습을 확인했다.
문제
이렇게 '나이브'한 TF-IDF는 중간평가를 위한 MVP를 개발하고 테스트 후 몇 가지 문제가 발견되었다. 먼저 수식을 다시 살펴보자.

이 수식을 사용하면서 깨달은 문제점은 다음과 같다.
- 기존의 문서 집합(이하 Corpus)은 과목마다 수능 특강 개념 몇 페이지 정도의 데이터만 저장되어 있었다. 때문에 계산되는 TF-IDF 값의 품질이 좋지 못하다.
- 문서에서 등장하는 단어의 빈도에 지나치게 민감하다. TF 값은 해당 단어가 해당 문서에서 얼마나 자주 등장하는지 빈도수를 단순하게 측정한 것이다. 따라서 문서에서 특정 단어가 지나치게 많이 등장한다면 그 단어는 매우 큰 TF 값을 갖게 될 것이고 그 단어의 최종 TF-IDF 값 또한 너무 커질 것이다.
- 과목 별로 가중치를 다르게 두지 않는다. “충성”이라는 단어는 역사 과목에서 그리 중요하지 않을 것이지만 윤리와 사상 과목에서는 훨씬 중요해질 것이다. 같은 단어라도 과목마다 중요도가 달라진다.
해결
이 세 문제를 가중치 알고리즘에서 고쳐야 할 가장 시급한 문제로 정의하고 다음 세 방법으로 해결하였다.
- 수능 특강의 모든 개념 페이지를 수집해 과목 별, 단원 별로 Corpus 에 저장한다. 또한 한국지능정보사회진흥원에서 제공하는 “AIHub”의 데이터를 사용해 일반 문서 데이터 또한 확보하고 DB화 하였다.
- 단순한 TF-IDF 알고리즘을 엘라스틱서치가 개발하여 사용하는 BM25 알고리즘으로 교체하였다.
- LLM 을 사용해 과목마다 핵심 단어들을 미리 선정하여 DB 에 넣었다. 이용자의 문서에서 과목 데이터를 확인할 수 있을 때, 해당 과목의 키워드들과 비교할 수 있었다. 만약 이미 DB 에 존재하는 키워드라면 해당 단어의 가중치 하한선을 일정 수준 이상으로 끌어올려 해당 단어가 빈칸이 될 확률을 어느 정도 보장하였다.
corpus는 그 이전에 13개의 문서와 1만 개의 단어를 저장하고 있었지만, 이후 총 631개의 문서와 120만 개의 단어를 저장하게 되었다. 또한 인공지능이 생성한 약 6000개의 키워드를 저장하였다.

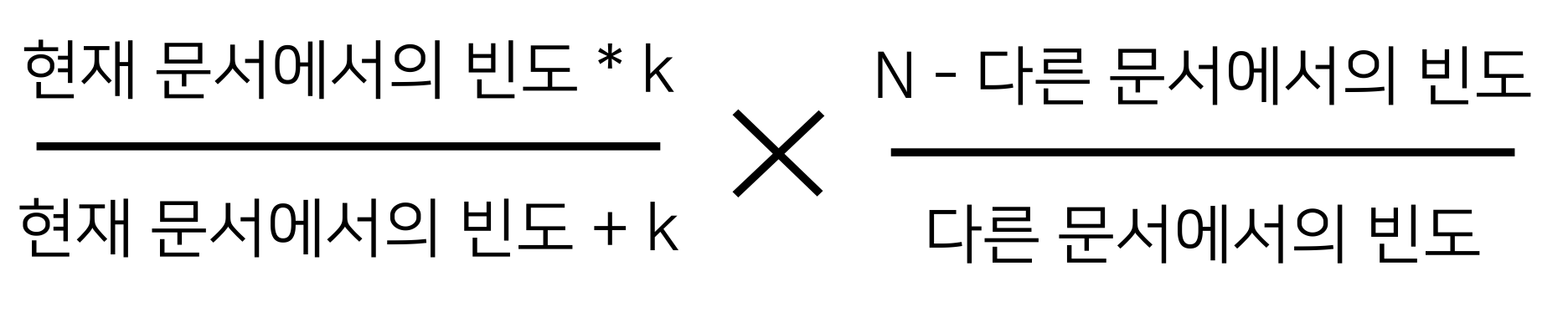
특히 BM25의 자세한 계산식은 위와 같다. 현재 문서에서의 빈도가 어느 정도까지만 영향을 미친다. 방대한 corpus 데이터베이스와 더불어 개선된 수식을 사용해 더 나은 결과를 확보할 수 있었다.
3번의 경우, BM25의 값을 기존의 딕셔너리 방식이 보조하는 형태로 구현한 것이다. 특히 기존 방식처럼 일일이 키워드를 선정하고 임의의 가중치를 부여하는 방식이 아닌, LLM을 사용해 대량의 키워드를 생성하고 따로 가중치를 설정하지 않고 하한선으로 동작하게 함으로써 키워드의 가중치가 기준이 불분명하다는 단점을 배제할 수 있었다.
개선 결과
개선사항의 결과는 다음과 같다. 그 이전보다 훨씬 사람과 비슷하게 빈칸을 생성한 것을 볼 수 있었다.

최종적으로 구축된 가중치 서버의 구조를 표현하면 다음과 같다.

아쉬운 점
단어 가중치 서버를 만들며 몇 가지 아쉬운 점이 있었다.
테스트의 체계, 타당도와 신뢰도를 확보하지 못했다.
테스트는 한국사 개념 1페이지를 사용해서 진행되었고 이상적인 목표치는 우리가 직접 빈칸을 친 문제지로 설정하였다. 하지만 학술적인 의미에서는 이 정도 테스트 셋은 매우 빈약하다고 볼 수 있다. 이상적인 테스트 결과를 위해 한국사라는 과목은 적절했지만 다른 과목에서 어느 정도 효과를 보이는지 제대로 확인하지 않았다. 따라서 결과가 올바르다고 해도 그것은 한국사에 국한된 결과일 뿐이다.
목표치 또한 매우 주관적이다. 사람이 빈칸을 친 문제지를 목표치로 삼는다해도 적어도 개발자 몇 명이 만든 문제지가 아닌, 다양한 전문가가 만든 문제지를 채택해야 했다.
따라서 테스트 셋과 목표치가 믿을 만 하지 않으므로 테스트 결과 또한 한국사에 국한되거나 아예 신뢰하기 어렵다. 물론 우리의 목표가 학술적 성과가 아닌 빠른 서비스 출시였기 때문에 이런 정도로 만족했지만, 그럼에도 불구하고 결국 품질 높은 가중치 서버를 만들려면 역시 높은 품질의 테스트를 진행했어야 했다.
가중치 알고리즘이 우리의 목적에 잘 맞지 않았다.
사실 TF-IDF와 BM25는 단어 각각의 중요도를 평가하기보다는 어떤 문장에서 어떤 단어가 중요한지 판단하기 위한 알고리즘이다. 검색어 문자열에서 어떤 단어가 중요하며 어떤 단어를 무시해도 되는지 판단하는 방식이다. 특히 BM25는 이러한 배경 때문에 입력 문자열의 길이 또한 가중치에 영향을 미친다. 물론 이 부분은 구현에서 제거했지만, 그럼에도 알고리즘 탄생 배경 자체가 우리의 목표와 빗나가는 바람에 우리 프로젝트에 최적화된 결과를 보여주진 못했다.
또한 과연 알고리즘으로 이 문제를 해결하는 것이 효과적인지 의문이 남는다. 많은 AI 기술들이 발전했고 개중에는 단어의 중요도를 예측하는 모델 또한 존재할 것이다. 하지만 우리 팀에 AI 전문가가 없어서 ChatGPT API 이상의 기술을 사용하지 못했다. AI를 사용하면 마케팅과 같은 측면에서도 많은 어필이 가능했을텐데 많이 아쉽다.
당시 상황에서 가중치 서버에 이렇게까지 맨아워를 쏟아야 했는지 의문스럽다.
위에서 소개한 BM25 테스트 결과는 확연히 좋은 방향으로 발전했지만, 사실 실제 테스트 데이터들을 모두 모아 살펴보면 저 결과가 가장 좋은 결과만을 소개했다는 것을 바로 알 수 있다. 생각보다 기존 TF-IDF보다 드라마틱한 발전은 없었다. 이후에도 개선에 노력을 쏟았지만 크게 얻은 과실은 없었다.
이러한 상황에서 단어 가중치 서버에 노력을 쏟기보다는 프론트 UI에 더욱 집중하는게 낫지 않았는가 싶다. 개인적으로 최종결과물의 UI/UX가 만족스럽지 않았고 동일한 피드백 또한 여러 번 들어왔다. 이 부분을 보완하는데 시간을 썼으면 더 나은 결과물을 얻을 수 있지 않았나 싶다.
마무리
이러니 저러니 해도 많은 시간과 노력을 쏟았고 반대로 많은 깨달음과 기쁨을 얻은 작업이었다. 작게나마 마이크로서비스가 어떻게 상호작용하는지 경험해볼 수 있었고 메세지 큐가 없는 현재 상황의 한계 또한 겪어볼 수 있었다. 벌써 수료한 지 2주가 넘어가는데 더 늦기 전에 글을 써낼 수 있어서 다행이다.
'IT > 서버' 카테고리의 다른 글
| Diary 프로젝트 일기 (3) (1) | 2025.04.05 |
|---|---|
| Diary 프로젝트 일기 (2) - CI/CD 파이프라인 (0) | 2025.02.26 |
| 알리에서 산 컴퓨터로 나만의 라우터 만들기 (0) | 2024.08.19 |
| AWS Multipart 파일 업로드 시 403 오류 해결 (0) | 2024.07.26 |
| 홈서버 변화사 (0) | 2023.11.09 |



