
altair의 프로젝트 일기
Operating Systems: Three Easy Pieces 리뷰 본문
개요
여러 리눅스 운영체제를 경험해 보면서 많은 것들을 깨달았다. 터미널도 익숙해지고, 파이프 사용법도 손에 익어온다. Vim도 꽤 쓸 수 있게 되었다. 작은 프로젝트는 조금 불편하지만 Vim으로도 충분히 작성할 수 있다. GUI 환경을 그놈에서 KDE로 바꾸거나 아예 없애버릴 수도 있게 되었다.
그러던 중 계속 머릿 속을 맴돌던 의문이 있었다. 이 모든 것의 밑 바닥에는 무엇이 있을까? 어떻게 프로그램이 실행되는 것일까? 운영체제도 프로그램이라면, 어떻게 프로그램 안에서 프로그램이 돌아가는 것일까? 그 프로그램들은 어떻게 동시에 실행될까? 이 모든 것을 누가 관리하는 것이지?
인간이 마치 신에 대한 물음을 던지는 것처럼 나는 자연스레 운영체제 그 자체에 대한 물음을 던질 수 밖에 없었다. 물론 내 목표가 리눅스 커널 개발자는 아니지만, 운영체제 안에서 무언가를 다루어야 한다면 그 보이지 않는 손에 대한 지식이 언젠가 도움되리라는 것은 분명하다. 여러 자료들을 검색해본 후 책 하나를 찾았다.
Operating Systems: Three Easy Pieces
Blog: Why Textbooks Should Be Free Quick: Free Book Chapters - Hardcover - Softcover (Lulu) - Softcover (Amazon) - Buy PDF - EU (Lulu) - Buy in India - Buy Stuff - Donate - For Teachers - Homework - Projects - News - Acknowledgements - Other Books Welcome
pages.cs.wisc.edu
한국어로 번역하면 '운영체제: 아주 쉬운 세 가지 이야기'가 되겠다. 불행히도 한국어 번역본은 절판된 것으로 보인다. 저자가 홈페이지에 무료로 책을 풀어서 자유롭게 보고 공부할 수 있었다.
며칠 전 이 책을 드디어 다 읽었다. 생각나는 대로 글을 써보겠다.
주제
가상화
먼저 가상화에 관련한 이야기부터 시작한다. 가상화는 프로그램이 컴퓨터 자원을 사용하는데 있어서 굉장히 중요한 요소인데, 우리는 여러 프로그램이 동시에 실행되기를 바라기 때문이다. 만약 컴퓨터를 계산기 역할로만 사용한다면 가상화 기술은 필요하지 않다. 계산기 프로그램만 실행되면 충분하기 때문이다.
그러나 계산기에겐 지나치게 과분한 컴퓨팅 자원이 손에 있으므로 우린 계산기가 음악 플레이어, 웹 브라우저, 게임용 메신저, 파일 매니저, 심지어는 클라우드 저장소 클라이언트와 실시간 날씨 어플까지 동시에 실행되길 원한다. 개발자에게 더욱 친숙한 예시가 있다면 AWS와 같은 클라우드 컴퓨팅 서비스가 아닐까. 모든 사용자에게 컴퓨터 한 대씩 할당한다면 나같은 학생에게는 얼마나 낭비일 것이며, 기업 사용자에겐 얼마나 부족하겠는가? 운영체제는 이러한 컴퓨팅 자원을 프로그램들에게 골고루 배분한다.
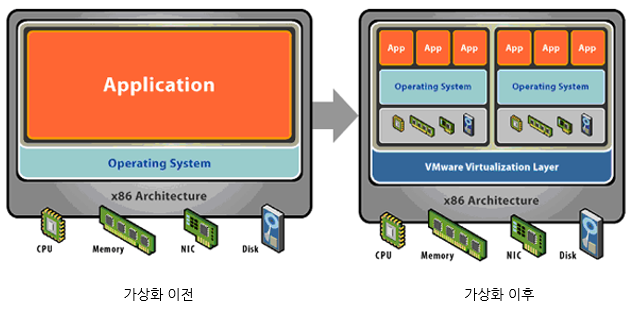
CPU 가상화
가장 먼저 CPU 가상화에 대해 알아보자. 프로그램 하나를 실행하는데 모든 CPU 자원을 동원한다고 상상해보자. 모든 프로그램 코드가 항상 CPU를 100% 사용하지는 않는다. 비교적 매우 느린 파일 입출력을 실행한다면 기다리는 시간은 CPU 입장에서 보면 영겁의 시간일 것이다. 오로지 CPU 자원만 사용한다고 해도 우린 여러 프로그램이 동시에 실행되길 바라지 않는가?
이런 이유로 운영체제는 스케줄링 정책을 사용해 프로그램의 CPU 사용 시간, 사용 사이클을 분배한다. 빨리 끝나는 작업을 우선적으로 할당하거나, 먼저 요청한 작업을 먼저 할당하는 것이다. 이에 대해 여러가지 방법이 존재한다. 예를 들어 멀티레벨 피드백 큐(MLFQ) 알고리즘을 사용하거나 추첨 스케줄링(Lottery) 등을 사용할 수 있다. 게다가 멀티코어 CPU 환경에서는 스케줄링이 더욱 흥미로워진다. 한 프로그램(프로세서)이 여러 코어를 옮겨다닐 수 있기 때문이다.
어찌 되었건 이런 방법을 통해 운영체제는 여러 프로그램이 동시에 실행될 수 있게 만든다. 중요한 점은 어떤 방법도 은 탄환이 될 수 없으며 책에서 말했다시피 중요한 점은 최선을 실현하는 것이 아니라 재앙을 피하는 것이다.
메모리 가상화
운영체제는 프로그램이 사용하는 메모리 자원도 가상화한다. 프로그램 수가 적다면 프로그램들이 서로의 메모리 영역을 침범하지 않으면서 메모리의 물리적 주소를 참조할 것이다. 하지만 만약 실수한다면 다른 프로그램의 메모리 영역을 침범하거나 악의적으로 사용할 수 있을 것이다. 개발할 때 까다로워지는 것은 덤으로 말이다.
운영체제는 프로세스를 고립시키고 보호하기 위해, 그리고 메모리 자원을 사용하기 쉽게 하기위해 가상메모리를 지원한다. 이는 프로그램이 자신의 코드와 데이터가 자기만의 메모리에 저장되어 있다는 환상을 제공한다.
메모리 공간을 가변크기 청크로 분할하거나(세그멘테이션) 동일한 크기의 조각으로 분할하여(페이징) 각 프로그램에게 할당한다. 특히 페이징은 자주 사용되는데, 성능 저하를 막기 위해 변환-색인 버퍼(Translation-Lookaside Buffer)라는 캐시 하드웨어를 사용한다. 자주 참조하는 가상주소와 실주소의 변환 데이터를 저장하는 캐시다.

메모리 가상화는 여기서 끝나지 않는다. 우리는 프로그램에게 무한한 메모리가 있다는 환상을 심어주고 싶다. 물리 메모리의 크기를 극복하고자 한다. (거의)무한한 메모리를 위해서는 어떻게 해야할까? 운영체제는 자주 사용하지 않는 메모리 상의 데이터를 보조 기억장치에 저장한다. 이 공간을 스왑 메모리라고 부른다. 나중에 해당 데이터가 필요해지면 다른 메모리 데이터와 교체하는 것이다. 이 교체 알고리즘도 여러가지가 있는데, 자세한 종류와 성능은 캐시 알고리즘에 관한 글을 참고하길 바란다.
GitHub - altair823/CachePolicyCompare: Comparison of different caching policies for implementing swap memory in operating system
Comparison of different caching policies for implementing swap memory in operating systems. - GitHub - altair823/CachePolicyCompare: Comparison of different caching policies for implementing swap m...
github.com
병행성
현대적인 멀티 스레드 프로세스에서는 병행성을 관리하는 것이 중요한 의미를 갖는다. 특히 가장 까다로운 부분은 여러 스레드 사이에서 데이터의 훼손을 방지하는 것이다. 데이터에 접근하는 명령어를 원자적으로 실행하기 바란다. 다음과 같은 방법을 책은 소개한다.
- 락: 한 스레드가 접근할 때, 데이터의 락을 획득하고 잠근다. 다른 스레드가 데이터에 또 접근한다면 잠겼기 때문에 락을 획득할 수 없다. 상호 배제(Mutual Exclusion)을 구현하므로 Mutex라고 부르기도 한다. 가장 많이 사용한다.
- 컨디션 변수: 어떤 실행상태가 참이 될 때까지 스레드가 대기하도록 하는 구조다. 만약 조건이 참으로 변경된다면 기다리던 스레드들을 깨운다. 락과 함께 병행성을 구현하기 위해 필요하다.
- 세마포어: 그 유명한 다익스트라가 만들었다. 1) 세마포어 값이 1이상이면 즉시 리턴하거나 세마포어 값이 1 이상이 될 때까지 호줄자를 대기시키는 함수와, 2) 세마포어 값을 증가시키고 대기 중인 스레드를 하나 깨우는 함수로 구성되어 있다.
- 이벤트 기반: node.js 의 이벤트 루프를 떠올리면 된다. 이벤트의 발생을 기다리고, 그 이벤트가 발생하면 작업을 처리한다. 느린 I/O 작업을 기다리면 전체 시스템이 멈추기 때문에 비동기 I/O를 사용한다.
이 모든 방법 역시 각자 장단점이 있으므로 환경에 따라 선택해야 할 것이다.
영속성
개인적으로 이 챕터가 가장 흥미로웠다. 파일의 관리와 백업, 파일 시스템의 구조 등에 평소 관심이 많은 탓이다. 이 책도 생각보다 놀라웠는데 하드디스크부터 SSD까지, 최신 RAID까지 다루었기 때문이다.
운영체제는 데이터를 외부의 보조기억장치에 저장한다. 이 과정은 CPU 입장에서 매우 느리다. 과거 하드디스크는 물론이고 최신 NVMe SSD도 CPU나 심지어 램에 비해서도 매우 느린 편이다. 이 느린 I/O를 기다리는 CPU를 다른 프로세스에 넘겨주고 결과가 올 때까지 기다린다. 인터럽트를 사용하거나 PIO로 이를 구현한다. PIO를 사용하면 데이터의 전송을 CPU가 담당하기 때문에 DMA라는 다른 특수한 연산장치로 이를 대신할 수 있다. CPU는 단지 다른 일을 하다가 DMA가 보낸 인터럽트를 감지하고 작업이 완료되었음을 알면 된다.
책은 또한 하드디스크의 자세한 작동 방식, 하드디스크 상에서의 데이터 전송 속도와 대역폭 분석을 소개한다. 그리고 이를 극복하기위한 RAID와 그 한계를 설명한다.
파일 시스템과 네트워크 파일 시스템도 소개한다. 가장 간단한 파일 시스템부터 현대적인 로그 기반 파일 시스템을 설명한다.
마무리
이번 학기에 운영체제 수업을 듣게 되었는데 미리 얕게라도 개념들을 알고 시작하게 되어서 다행이라는 생각이 든다. 그리고 그것과 별개로 운영체제가 굉장히 흥미로운 분야라는 것도 알게 되었다. 이 분야를 더 깊이 파보고 싶어졌다.
'IT > 책' 카테고리의 다른 글
| 은 탄환은 없다(No Silver Bullet)에 대한 생각 (0) | 2023.03.20 |
|---|
