
altair의 프로젝트 일기
운영체제의 캐시 정책 비교 본문
운영체제의 가상 메모리 부분을 공부하고 있을 때였다. 운영체제는 디스크와 같은 보조 저장장치 위에 올라간 스왑 메모리에 메인 메모리의 데이터를 저장하곤 한다. 당장 사용하지 않는 데이터가 메인 메모리를 계속 점유하고 있는 것은 비효율적이기도 하거니와 응용 프로그램으로 하여금 컴퓨터에 무한한 메모리가 있는 것처럼 보이게 하는 중요한 기술이다.
그런 측면에서 메인 메모리는 스왑 메모리에 대한 캐시 역할을 한다고 볼 수 있다. 지금 당장 요구하는 데이터를 메인 메모리에 올려 속도를 높이고, 그렇지 않은 데이터를 디스크에 옮겨 공간을 늘리는 방식이니까.

CDN이나 프록시 캐시같은 네트워크 캐시부터 CPU안의 캐시까지 세상엔 대단히 많은 캐시들이 있지만 모두 같은 목적을 갖고 있다. 사용자로 하여금 데이터에 더 빠르게 접근 할 수 있도록(캐시 히트) 하고 캐시에 존재하지 않아 원본 데이터를 불러오는 일(캐시 미스)을 최소한으로 줄이는 것이다. 간단히 말해 캐시 히트는 최대한으로, 캐시 미스는 최소한으로 발생시키고자 한다.
캐시 히트를 늘리는 가장 쉬운 방법은 캐시 크기를 늘리는 것이다. 만약 100개의 원본 데이터가 있고 100개의 데이터를 모두 저장할 수 있는 캐시가 있다면, 그리고 모든 데이터가 이미 캐시에 올라가 있다면 모든 데이터 접근은 캐시 히트일 것이다. 하지만 현실적으로 이런 크기의 캐시를 만드는 것은 비쌀 뿐만 아니라 비효율적이다. 캐시 크기에 비해 여전히 자주 요청되는 데이터는 훨씬 일부분일 것이고 나머지 데이터는 많은 시간 동안 그저 자리만 차지하고 있을 뿐이다. 또 캐시 크기가 증가하면서 데이터를 저장하고, 탐색하고, 불러오는데 더 많은 시간이 필요해질 수 있다. 최악의 경우엔 결과적으로 또 다른 원본 저장소를 만드는 것과 다를 바 없게 된다.
이런 이유로 캐시의 크기를 늘리는 건 한계가 있다. 많은 사람들이 예상하듯 캐시가 꽉 찼을 때 어떤 데이터를 유지하고 어떤 데이터를 다른 원본과 교체할 것인지 결정하는 방법이 중요해진다. 이것을 캐시 정책이라고 하는데 데이터와 서비스의 종류에 따라 달라질 수 있다.

다음은 운영체제에서 사용하는 캐시 정책의 간단한 버전들이다.
- 무작위 캐시
- FIFO 캐시
- 접근 횟수 기반 캐시(LFU cache)
- 접근 시간 기반 캐시(LRU cache)
이번 프로젝트에선 무작위 캐시, FIFO 캐시, 그리고 LRU 캐시를 구현하고 비교해 보았다.
GitHub - altair823/CachePolicyCompare: Comparison of different caching policies for implementing swap memory in operating system
Comparison of different caching policies for implementing swap memory in operating systems. - GitHub - altair823/CachePolicyCompare: Comparison of different caching policies for implementing swap m...
github.com
최적 캐시
최적 캐시는 현실에 존재하지 않는 캐시다. 단지 테스트 상황에서 특정 크기의 캐시가 이론적으로 달성할 수 있는 최고의 효율을 보여주기 위한 장치다. 이번 프로젝트에선 Belady의 알고리즘을 사용했다. 이 알고리즘은 모든 데이터 요청의 순서를 미리 알고 있다는 가정 아래 동작한다. 간단히 과정을 설명하자면 다음과 같다.
만약 캐시가 이후에 사용될 모든 데이터와 그 순서를 알고 있다면 어떨까? 캐시는 가장 효율적인 방법을 찾아 데이터를 교체할 수 있다. Belady는 그 교체 방식은 단지 가장 나중에 요청할 데이터 먼저 교체하면 그것이 가장 효율적인 캐시라는 것을 증명했다. 즉, [1, 2, 3, 4, 2, 1, 2, 3, 1, 4] 순으로 페이지를 요청하고 크기가 3인 캐시가 비어있다고 하자. 과정은 아래에 보인다.
- 처음 세 번의 요청은 무조건 캐시 미스를 일으킨다. 어쩔 수 없는 미스다.
- 그 이후에 캐시에는 {1, 2, 3}이 들어있다.
- 4를 요청했지만 캐시에 없다. 캐시 미스가 발생한다. 캐시는 1, 2, 3 중에 4와 교체될 데이터를 선택해야한다.
- 1, 2, 3 중에서는 3이 제일 나중에 요청될 것이다. 따라서 3을 4와 교체한다. 캐시: {1, 2, 4}
- 이후 세 번(2, 1, 2)은 캐시 히트다.
- 3을 요청했지만 캐시에 없다.
- 2가 제일 나중에 요청될 것이므로 2를 3과 교체한다. 캐시: {1, 3, 4}
이런식으로 최적 캐시는 캐시 미스를 최소화 할 수 있다. 하지만 현실 세계에서 모든 요청을 미리 정확하게 예견할 수는 없다. 그래서 이 캐시는 비교를 위해 존재하는 것이다.
무작위 캐시
무작위 캐시는 말 그대로 교체 대상을 무작위로 선정한다. 듣기엔 별로 안 좋아보이지만 나름 장점을 가진다. 먼저 구현이 매우 간단하다. 그리고 많은 리소스를 잡아먹지 않는다. 단지 아무거나 집어서 교체하면 그만이다.
FIFO 캐시
FIFO 캐시의 FIFO는 first-in-first-out 이라는 뜻으로 큐 자료구조에서 많이 보는 약자다. 이 캐시는 마치 큐처럼 작동한다. 가장 처음 들어온 데이터를 가장 먼저 교체한다. 이 역시 무작위 캐시처럼 구현이 간단하다. 하지만 이 캐시는 특정 요청 패턴에서 크기가 증가할 수록 캐시 미스가 오히려 증가한다는 Belady의 역설의 문제를 안고 있다.
LRU 캐시
최적 캐시처럼 미래의 모든 요청을 예측 할 수는 없지만 과거의 정보에 기반해 미래 요청의 가능성을 예측 할 수는 있다.
char arr[ARR_LEN];
unsigned int counter = 0;
for (int i = 0; i < ARR_LEN; i++) {
arr[i] = i;
counter++:
}위 코드를 예시로 들어보자. 만약 arr 위치의 데이터가 요청되었다고 가정하자. 그렇다면 arr+1의 데이터도 요청될 가능성이 높다. 이어서 arr+2도 가능성이 높다. 배열과 같은 선형 데이터 때문이며, 배열 접근이 메모리 접근 중에서 얼마나 많은 비율을 차지하는지 말 안해도 알 것이다. 이를 공간적 지역성이라 한다.
또 다른 예시를 들어보자. 데이터 i가 반복문이 시작할 때 요청되었다. 얼마 후 i는 금방 다시 요청될 확률이 높을 것이다. 위 반복문이 계속되는 동안 i라는 변수는 계속 요청될 것이다. counter는 또 어떤가? 만약 외부에서 선언된 변수가 반복문 안에서 한번이라도 요청된다면 그 변수는 반복문이 반복하는 내내 요청될 것이다. 이를 시간적 지역성이라고 한다.
이런 데이터 요청의 지역성을 고려하면, 과거 정보를 사용해 미래에 어떤 데이터가 또 요청될 것인지, 그래서 어떤 데이터를 캐시에 남겨둬야 하는지 알 수 있다.
LRU 캐시는 Least-Recently-Used라는 뜻으로, 가장 오래 전에 사용했던 데이터를 교체한다. 시간적 지역성을 이용하는 것이다. FIFO 캐시가 얼마나 최근에 요청되었건 상관없이 가장 먼저 들어왔던 데이터를 교체하는 것과 다르게 LRU 캐시는 데이터가 요청될 때마다 그 데이터의 교체 순위가 밀린다고 생각하면 된다.
테스트 환경
모든 테스트 환경에서 캐시 크기는 1 부터 100까지 증가하며 매 캐시 마다 10000번 데이터를 요청했다. 데이터는 0부터 99까지 100개가 존재한다.
- 무작위 요청 - 모든 요청은 무작위적이다.
- 80 대 20 요청 - 80%의 데이터는 20%의 빈도만큼 요청하고, 20% 페이지는 80%의 빈도만큼 요청한다.
- 순환형 순차 요청 - 0부터 49까지의 데이터를 순차적으로 요청한다. 49까지 요청했으면 다음은 다시 0부터 시작한다.
테스트 결과
무작위 요청
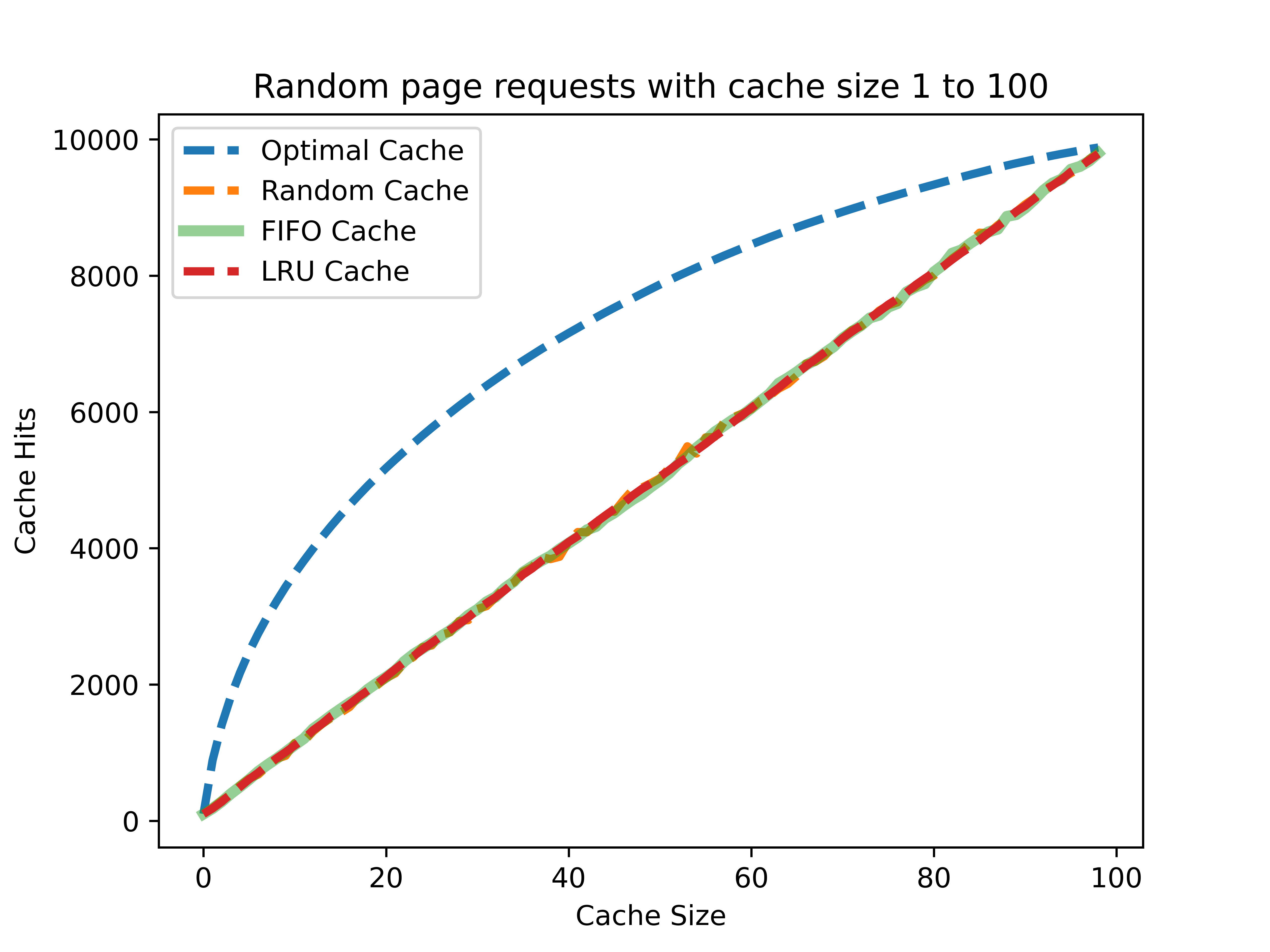
최적 캐시를 제외한 모든 캐시가 비슷한 성능을 보이고 있다. 미래의 요청을 과거의 어떤 정보로도 예측할 수 없기 때문이다. 오직 모든 미래 요청을 알고 있는 최적 캐시만 좋은 성능을 보인다. 또한 이런 무작위 요청 상황에서는 캐시 크기가 캐시 히트에 있어서 가장 중요한 요소가 된다는 것을 알 수 있다.
80 대 20 요청
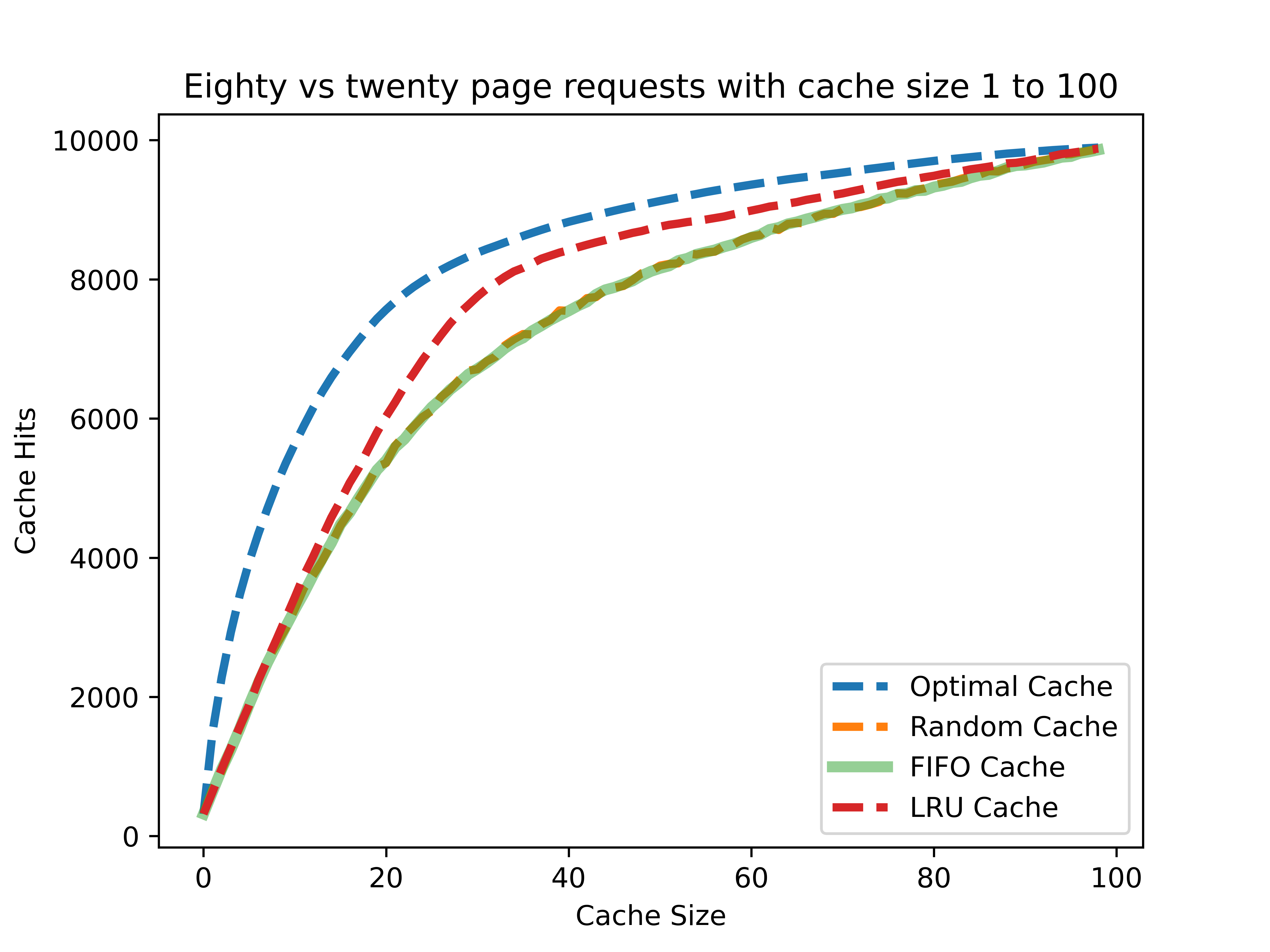
80 대 20 요청 상황은 앞서 보인 무작위 요청보다 훨씬 현실에 가깝다고 할 수 있다. 그 중에서도 자주 요청한 데이터가 미래에 또 다시 요청될 것이라는, 반복문에서 보인 시간적 지역성을 테스트하는 환경이다.
그래프에서 보다시피 무작위 캐시와 FIFO 캐시보다 LRU 캐시가 더 좋은 성능을 보인다.
순환형 순차 요청
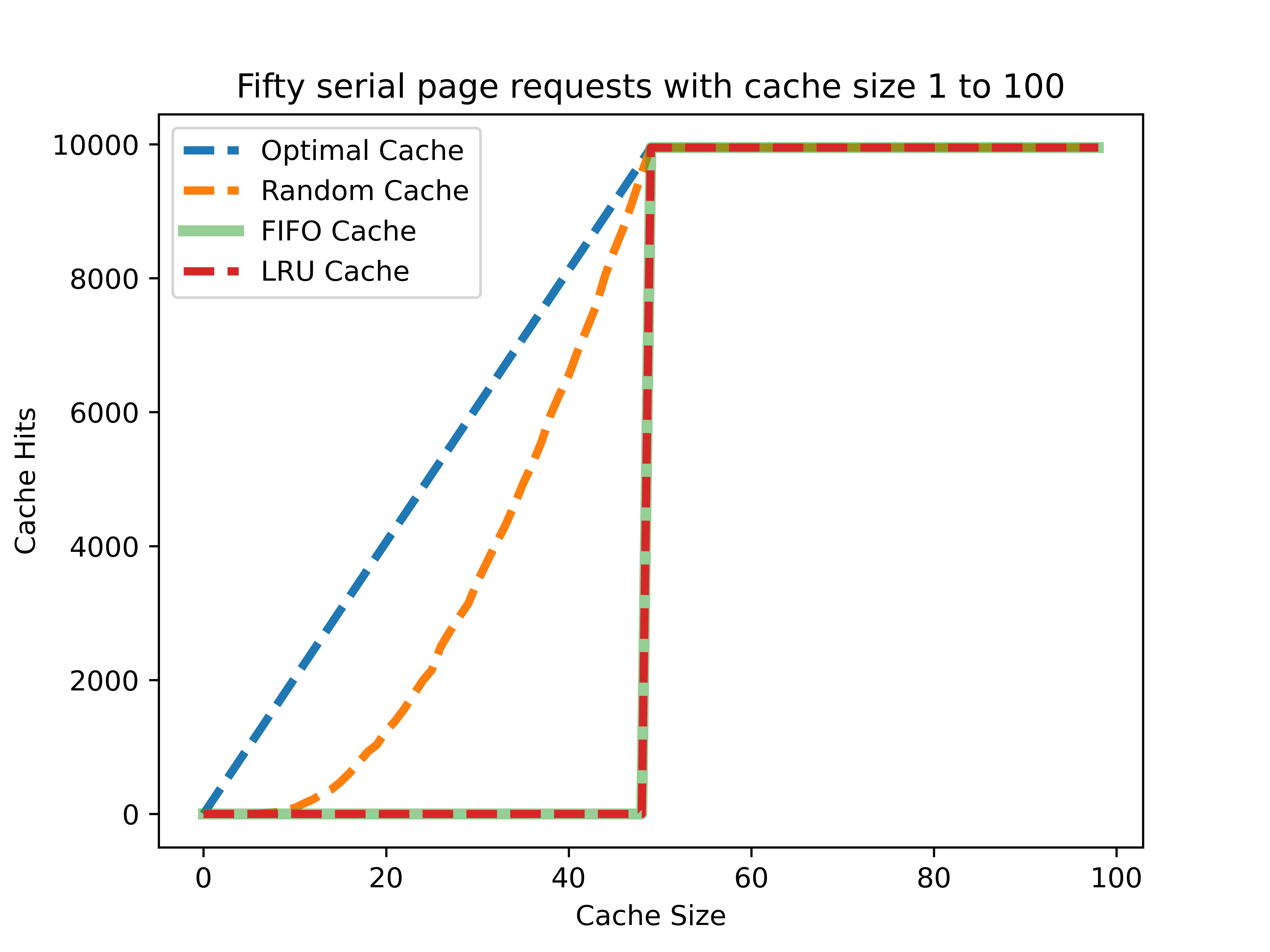
순환형 순차 요청은 공간적 지역성과 연관이 있다. 마치 배열에 접근하듯이, 0부터 49까지 데이터를 연속해서 접근한다.
이 상황은 좀 더 흥미롭다. LRU와 FIFO 캐시는 순차요청에서 랜덤 캐시보다 훨씬 못한 성능을 보인다. 그 둘은 가장 오래된 데이터를 교체하는데, 이 상황에서는 캐시 크기가 50을 넘을 때까지 단 한순간도 캐시 히트를 발생시킬 수 없다는 말이다. 따라서 무작위적으로 히트를 발생시키는 랜덤 캐시가 더 나은 성능을 보이는 것이다.
결론
이제 결과들을 보고 결론을 내려보자.
- 무작위적인 요청에서는 미래를 예지하지 않는 이상 캐시 크기가 캐시 정책보다 큰 의미를 가진다.
- 과거의 요청 데이터를 활용하여 시간적 지역성을 이용하면 더 나은 성능을 기대할 수 있다.
- 배열과 같이 공간적 지역성을 제대로 활용하기 위해서는 요청될 데이터 묶음 전체를 저장할 만큼의 캐시 크기가 확보 되어야 한다(또는 일부분이라도 확실히 캐시에 유지해 놓아야 한다).
이번 프로젝트를 통해 캐시들을 만들어보고 거기에 사용하는 알고리즘을 직접 구현해보는 기회가 되었다. 또한 데이터의 지역성을 어떻게 활용할 수 있는지 배울 수 있었다.
'IT > 파이썬' 카테고리의 다른 글
| SQLite 기반 set과 queue(나무위키 크롤링) (0) | 2024.03.23 |
|---|
