
altair의 프로젝트 일기
비정형 기계와 유전 알고리즘 본문
1. 개요
저번 글에서는 튜링이 자신의 논문에서 제시한 비정형 기계를 이야기했다. 이번 글에서는 그 비정형 기계의 Unit(이하 소자)과 Edge(이하 간선)를 갖고, 역시 튜링이 제시한 기초적인 유전 알고리즘을 테스트한 결과를 보이려한다.
유전 알고리즘은 자연에서 흔히 볼 수 있는 자연선택을 모방하여 더 나은 결과를 얻어내기 위한 알고리즘이다. 여러 개체를 생성하고 그들을 특정 방식으로 선택한 뒤, 교배와 변이를 통한 다음 세대를 만들어내는 과정을 통해 결국 환경에 가장 적합한 개체를 얻어내는 방식으로 작동한다. 즉, 유전 알고리즘은 기본적으로 선택, 교차, 변이, 대치와 같은 연산을 포함하는 것이다.
이번 프로젝트에서는 충분히 복잡한 비정형 기계를 여러 개 생성한 다음 이들로 하여금 유전 알고리즘으로 원하는 기계가 나올 때까지 여러 세대 돌려보았다. 먼저 한 세대의 흐름을 보이자면 다음과 같다. 개체들 간의 교차는 해를 찾기 위한 중요한 작업이지만, 이번 프로젝트에서는 구현하지 않았다.
1. 각각의 기계가 가진 하나의 간선을 변이시킨다. 이는 간선이 상태 값을 반전시켜 전달하도록 한다. (변이)
2. 모든 기계의 결과 값을 계산한다.
3. 결과 값에 따라 순위를 매긴다. (선택)
4. 미리 정한 k개 만큼 하위 기계를 제거한다.
5. 상위 기계들을 차례대로 k개 만큼 복사하여 생성한다. 기계들의 기존 개수를 회복한다. (대치)
2. 테스트 설계
기계를 선택하기 위해서는 기계의 어떤 부분의 상태가(또는 여타 다른 속성이) 환경에 얼만큼 적합한지 판단할 수 있어야 한다. 다음 그림은 이번 프로젝트에서 사용한 비정형 기계의 구조다. 각 소자는 두 입력 간선을 가지며, 두 입력을 NAND 연산한 값을 현재 값으로 갖는다. 그림에서 빨간색 O는 기계의 출력 값에 해당하는 소자들이다. 또한 화살표는 간선의 방향을 나타내며 간선에서 입력받지 않는 소자는 초기 상태를 그대로 갖고 연산하지 않는다.

어떤 기계의 출력 값이 10110101으로 나왔고 목표하는 값이 00000000이라면, 기계가 환경에 적응한 정도는 3, 적응하지 못한 정도는 5라고 할 수 있을 것이다. 환경은 이 정도 값을 이용해 여러 기계들을 줄세우고 선택, 대치할 수 있었다.
이번 프로젝트에서 사용한 기계는 다음의 조건을 갖는다.
1. 결과 값은 상태를 다른 소자에게 주지 않는 말단 소자 8개(위의 그림에서 빨간 동그라미 소자)를 각각 비트로 해석한 8자리 이진수이다.
2. 입력 값 8자리 이진수로, 다른 소자에게서 상태를 받지 않는 루트 소자 8개의 초기상태에 각각 대응된다.
3. 결과 값은 펄스가 세 번 발생한 이후의 말단 소자들의 상태로 정의한다.
4. 입력 값은 1111 1111로 정의한다.
5. 목표 값은 입력 값과 가장 먼 0000 0000으로 정의한다.
6. 한 세대가 지날 때마다 간선 하나에 변이가 일어나며 해당 간선은 상태를 반전해 전달한다. 기존에 변이가 이미 일어났다면 다시 원상태로 돌아온다.
또한 한 세대가 지날 때마다 실행하는 연산은 다음과 같다.
1. 모든 기계들을 변이시킨다.
2. 결과 값과 목표 값의 차이에 따라 기계들을 정렬한다. 만약 차이가 0인 기계가 나타나면 2-1로 간다.
3. 비트가 가장 많이 차이나는 k개의 기계를 제거한다.
4. 비트가 가장 적게 차이나는 기계 순으로 하나 씩, 총 k개를 새로 복제한다. 이를 통해 원래 기계 수를 회복한다.
5. 기계들을 초기화한다.
2-1. 해당 회차를 반환하고 세대 반복을 중단한다.
이 과정에서 모든 기계의 결과 값과 목표 값의 차이를 로그파일에 세대마다 기록한다. 반복이 끝나고 로그파일을 분석해 그래프를 작성할 수 있었다.
테스트 환경은 다음 네 개이다.
1. 4개의 기계, 세대마다 1개 탈락
2. 10개의 기계, 세대마다 1개 탈락
3. 10개의 기계, 세대마다 4개 탈락
4. 10개의 기계, 세대마다 9개 탈락
5. 20개의 기계, 세대마다 10개 탈락
3. 테스트 결과
결과를 차례대로 나열하면 다음과 같다. 테스트 결과는 각각 두 개씩 제시하며, 다른 테스트에서는 또 다른 결과가 나타날 수 있다.
1. 4개의 기계, 세대마다 1개 탈락
1-1. 1번 째 시행

1-2. 2번 째 시행

2. 10개의 기계, 세대마다 1개 탈락
2-1. 1번 째 시행
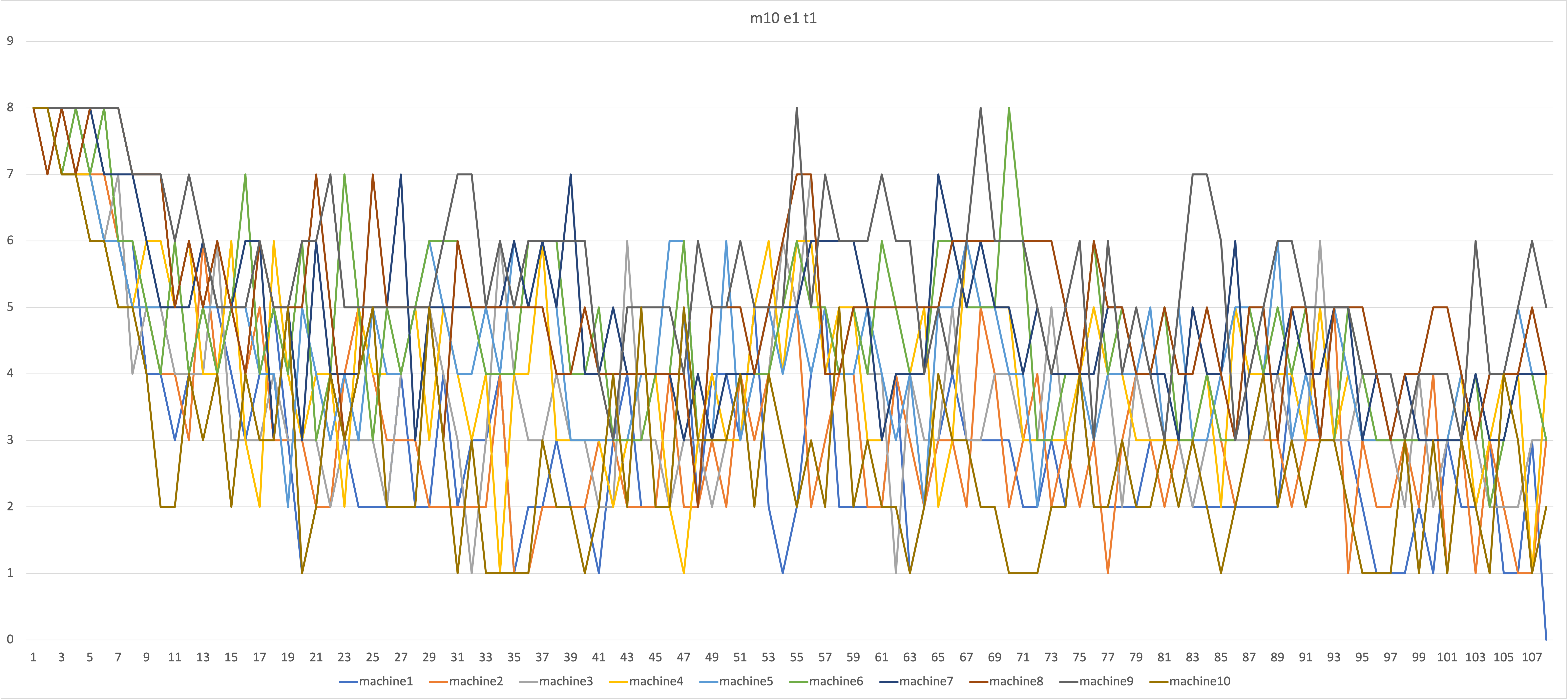
2-2. 2번 째 시행
3. 10개의 기계, 세대마다 4개 탈락
3-1. 1번 째 시행

3-2. 2번 째 시행

4. 10개의 기계, 세대마다 9개 탈락
4-1. 1번 째 시행

4-2. 2번 째 시행

5. 20개의 기계, 세대마다 10개 탈락
5-1. 1번 째 시행

5-2. 2번 째 시행

4. 결과 분석
먼저 1번 결과를 보자. 풀의 크기가 작다보니 원하는 결과가 나오기까지 많은 세대가 필요한 것을 알 수 있다. 또한 교차의 과정이 없기 때문에 어느 정도 수준 이하로 차이가 잘 내려가지 않는 모습을 보인다. 반대로 5번 결과를 보면 풀의 크기가 충분히 큰 관계로 훨씬 적은 세대만에 원하는 기계가 등장한 것을 알 수 있다. 기계의 결과 값 분포도 더욱 다양한 것을 볼 수 있다.
2, 3, 4번 결과는 함께 보도록 하자. 가장 적은 세대를 요구하는 설정은 3번이다. 2번은 세대마다 제거하는 기계가 1개, 4번은 9개라는 것을 고려하면, 알고리즘의 최적화를 위해서 탈락자 수를 적절히 설정해야 한다는 것을 알 수 있다.
또한 2, 4번 결과를 비교해보면, 2번 결과에서는 한 세대에서 가장 큰 차이 값과 가장 작은 차이 값이 많게는 6까지 차이나는 것을 알 수 있다. 반대로 4번 결과에서는 차이 값의 분포가 일정한 것을 알 수 있으며, 최대값과 최소값의 차이가 4를 넘지 않는 것을 알 수 있다. 이는 한 세대의 탈락자 수와 관련이 있다고 볼 수 있을 것이다. 탈락자가 적을 수록 목표 값과 차이가 많이 나는 다양한 기계들이 계속 생존할 수 있을 것이며, 탈락자가 많을 수록 차이가 많이나는 기계가 살아남을 수 없을 것이다.
결과를 종합하면 다음과 같다.
1. 기계의 수가 많을 수록 원하는 기계가 나올 확률이 높아진다.
2. 탈락자 수를 적절히 설정해야 최소한의 세대만에 원하는 기계를 얻을 수 있다.
3. 탈락자 수는 기계들의 다양성과 관련이 깊다.
5. 결론
프로젝트 결과를 현실로 가져와보자.
1. 진화의 대상이 되는 개체의 수가 많을 수록 환경에 적응하는 개체가 등장할 확률이 높아진다.
2. 환경의 적절한 수준의 압력은 종족의 빠른 적응에 필수적이다.
3. 환경의 압력이 너무 크면 종족의 다양성에 치명적이며, 압력이 작으면 많은 수의 개체의 빠른 적응에 부적인 영향을 미친다.
비록 단순하고 성급한 결론일 수 있지만, 프로젝트의 결론은 현실 세계에서 보이는 모습을 어느 정도 보여준다. 여러 지역에 퍼져 있으면서 많은 개체 수를 확보한 종족은 여러 모습으로 각자의 환경에 쉽게 적응할 수 있었다. 개미를 비롯한 곤충들과 여러 동식물들을 굳이 언급할 필요도 없을 것이다.
환경의 압력에 의해 종의 다양성이 피해를 입은 경우 또한 쉽게 생각할 수 있다. 환경의 압력은 결과적으로 '어떤 개체가 살아남을지를 환경이 얼마나 강하게 요구하느냐'라고 할 수 있다. 여기에는 기후나 서식지 뿐만 아니라 인위적인 개체수 조절 또한 포함될 것이다. 우리가 먹는 바나나의 다양성이 얼마나 단순한지는 이미 유명한 이야기이다. 소와 돼지 같은 가축들, 우리가 먹는 곡식들도 자연 상태에 비해 아주 단순한 다양성을 가지고 있다. 모두 인간의 개체 수 조절이 환경의 압력으로서 작용한 결과이다.
6. 참고
GitHub - altair823/EvolutionMachine
Contribute to altair823/EvolutionMachine development by creating an account on GitHub.
github.com
- 유닛 레이아웃 파일
'IT > 기타' 카테고리의 다른 글
| 소프트웨어 마에스트로 15기 합격 후기 (0) | 2024.04.22 |
|---|---|
| MySQL을 사용한 중복 파일 관리 프로그램 (0) | 2023.10.08 |
| 강의 자료를 동기화하면서 겪었던 시행착오들 (0) | 2023.04.07 |
| 비정형 기계 만들기 (0) | 2022.01.28 |
| M-disc로 아카이빙한 후기 (0) | 2021.12.05 |


