
altair의 프로젝트 일기
러스트로 tar 직접 구현하기 (2) 본문
개요
저번 글에서 기본적인 직렬-역직렬화를 구현했다. 파일을 단순히 저장하고 복원하기만 할 뿐이라면 굳이 더 뭔가 필요하진 않다. 하지만 만약 민감한 파일이나 너무 큰 용량의 파일을 저장할 때는 문제가 될 수 있다. 파일 데이터가 날 것으로 저장되기 때문에 마음만 먹으면 남들도 언제든지 파일을 복원하고 내용을 확인할 수 있다. 그래서 이번엔 데이터를 압축하고 암호화하는 과정을 설명하고자 한다.
압축
데이터 압축은 쉬운 문제가 아니다. 압축률과 시간, 메모리 사이의 적절한 트레이드오프가 필연적으로 발생한다. 압축률이 높다면 시간이 오래 걸리거나, 메모리를 많이 사용해야 하거나, 둘 다일 것이다. 반대로 시간을 짧게 쓰고 싶거나 메모리를 적게 쓰고 싶다면 압축률을 어느 정도 포기해야 한다.
다른 압축 프로그램으로 폴더 전체를 압축한다면 더 효율적인 압축이 가능하다. 그것이 불가능하다면 파일 하나를 모두 메모리에 올려 압축한다면 그래도 압축률이 괜찮을테다. 내가 만든 직렬화 코드는 파일을 하나씩 차례대로 읽으므로 파일 하나씩 메모리에 올려 압축하는 방법을 사용했다.
let mut compressor = ZlibEncoder::new(
BufReader::new(File::open(&original_file_path)?),
Compression::new(9),
);
let dir = destination_path.as_ref().to_path_buf();
fs::create_dir_all(&dir)?;
let mut t = original_file_path.as_ref().to_path_buf();
t.set_extension("zip");
let compressed_file_path = dir.join(t.file_name().unwrap());
let mut result = BufWriter::new(File::create(&compressed_file_path)?);
let mut buf = Vec::new();
compressor.read_to_end(&mut buf)?;
result.write_all(&buf)?;
result.flush()?;압축 라이브러리는 flate2를 사용했다. Zlib을 사용하는 compressor를 만들고 여기에 원본 파일 데이터를 넣어준다. 임시 폴더를 만들고 압축한 데이터를 그 안에 새 파일로 저장한다.
let compressed_file = compress::compress(original_file, TEMP_COMPRESSED_FILE_PATH)?;
self.result.write(&compressed_file.metadata()?.len().to_le_bytes().to_vec())?;
fs::remove_file(compressed_file)?;그리고 그 압축한 파일 데이터를 결과 파일에 쭈루룩 이어 쓰면 된다. 다 썼다면 압축된 파일을 지운다.
테스트 결과 LZMA2를 사용한 최고 압축률 압축 파일보다는 살짝 결과 파일의 크기가 컸지만, 파일 하나씩 압축한 결과치곤 괜찮은 크기를 보여줬다.
암호화
대표적인 암호화 방법에는 대칭키와 공개키 암호화 방식이 있다. 만약 이 파일을 인터넷을 통해 특정 대상에게 보낸다면 공개키 방식을 써야겠지만, 파일을 만들 사람이 암호-복호화 해야하는 경우 대칭키 방식이 더 적절할 것이다.
파일을 암호화하는 방법은 중요한 문제가 있다. 파일의 크기가 메모리에 비해 너무 크다면 파일을 어떻게 암호화 해야할까? 파일을 작게 쪼개 암호화하면 키가 노출되거나 원본 메시지가 노출될 위험이 있다. 또한 입력한 키를 바로 암호화에 사용하거나, 원본 메시지를 그대로 암호화하는 것 역시 매우 위험할 수 있다. 따라서 여러가지 추가적인 부분이 필요하다.
먼저 키를 이야기해보자. 사용자가 입력하는 암호는 그 길이가 들쭉날쭉하다. 이는 해시함수를 사용하여 길이를 일정하게 바꿀 수 있다. 하지만 암호를 바로 해시하면 해시 충돌을 사용해 원본 암호와 다르지만 복호화 가능한 암호를 얻을 수 있다. 예를 들어 1234를 해시해 9999라는 키를 얻었다고 해보자. 암호화는 9999라는 키를 사용해 이루어질 것이다. 이때 해커가 만약 0000부터 9999까지의 모든 해시 값에 대한 원본 값을 정리해 표로 만들었다고 해보자. 특히, 9999라는 해시 값에 대한 원본 값으로 5678을 갖고 있다면 1234라는 암호 대신 5678을 입력해 복호화 할 수 있다. 어차피 둘 다 9999라는 해시 값을 생성할 것이기 때문이다.
이를 막기 위해 암호의 앞, 뒤에 salt라는 무작위 문자열을 붙여 해시한다. 위의 예시를 그래도 사용해보자. 1234와 무작위 솔트값 8080을 사용해 9999라는 해시값을 얻었고 이것으로 암호화 했다고 하자. 이번에도 역시 해커가 마찬가지로 모든 해시값의 원본이 될 수 있는 값을 가지고 있다. 해커는 해시값 9999를 얻기 위해 어떤 값을 해시해야 하는지는 알고 있다. 하지만 솔트값 8080을 붙여서 해시값 9999를 만들 수 있는 원본 값은 모른다. 게다가 매번 키를 사용해 암호화할 때마다 새로운 무작위 솔트값이 사용된다. 이런 방식으로 해시 충돌 공격을 무력화 할 수 있다.
메시지 또한 바로 암호화하지 않는다. AEAD를 생성해 메시지를 암호화하는 과정에서 Nonce(메시지마다 새로 생성되는 무작위 일회용 숫자)가 필요하다. 이는 암호문이 정보를 누출하지 않을 수 있다.
암호화 라이브러리는 chacha20poly1305를 사용했다. 다음은 해당 라이브러리의 스트림 암호화 방식 다이어그램이다.
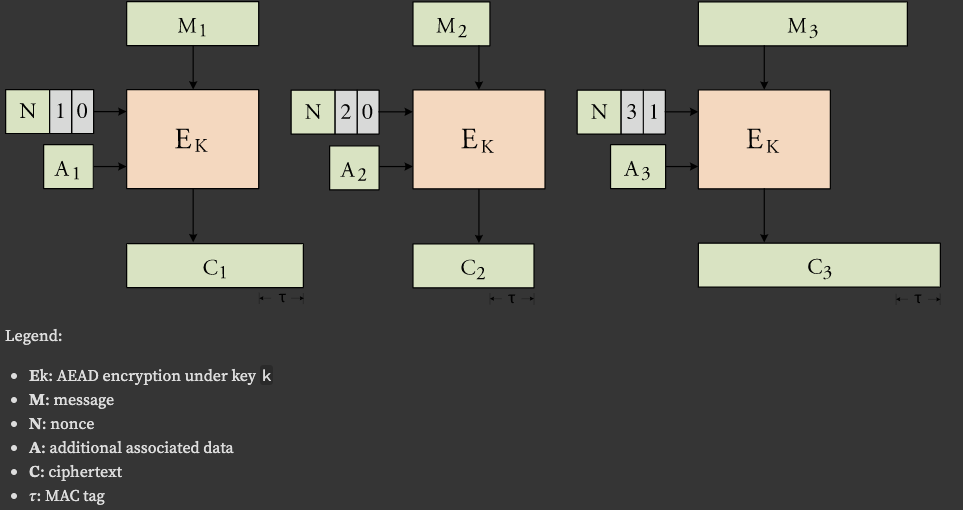
다이어그램을 잘 살펴보면 암호문에 타우가 더 붙어있는 것을 볼 수 있다. 모든 암호문 결과들에는 MAC 태그들이 달려서 나온다. 이는 각각의 암호문이 유효한지 검증하는 역할을 한다. 이는 보동 16바이트 길이를 갖는다.
파일은 부분으로 나누어 위와 같은 방식으로 암호화하면 된다. 그렇다면 암호화된 파일에는 어떤 데이터가 포함되어야 할까?
먼저 솔트가 포함되어야 한다. 솔트는 사용자로부터 암호를 입력받았을 때 복호화 키를 생성하기 위해 필요하다. 솔트는 굳이 숨길 필요없는데, 해시 충돌을 막기위한 장치일 뿐이기 때문이다. 또한 각 암호문마다 새로 생성되는 논스도 저장해야 한다. 논스는 복호화를 위한 AEAD Decryptor를 생성하기 위해 필요하다.
그리고 마지막으로 암호문을 저장하면 된다. 암호문을 복호화할 때 각 부분의 마지막 16바이트는 MAC 태그이므로 이것만 조심해 복호화 하면 된다.
키와 AEAD, 논스 등을 만드는 코드는 다음과 같다.
pub const NONCE_LENGTH: usize = 19;
pub const SALT_LENGTH: usize = 32;
pub fn make_nonce() -> [u8; NONCE_LENGTH] {
let mut nonce = [0u8; NONCE_LENGTH];
OsRng.fill_bytes(&mut nonce);
nonce
}
pub fn make_new_key_from_password(password: &str) -> (Vec<u8>, [u8; SALT_LENGTH]) {
let argon2_config = argon2::Config::default();
let mut salt = [0u8; SALT_LENGTH];
OsRng.fill_bytes(&mut salt);
let key = argon2::hash_raw(password.as_bytes(), &salt, &argon2_config).unwrap();
(key, salt)
}
pub fn make_key_from_password_and_salt(password: &str, salt: Vec<u8>) -> Vec<u8> {
let argon2_config = argon2::Config::default();
let key = argon2::hash_raw(password.as_bytes(), &salt, &argon2_config).unwrap();
key
}
fn make_aead(key: &[u8]) -> XChaCha20Poly1305 {
XChaCha20Poly1305::new_from_slice(&key).unwrap()
}
pub fn make_encryptor(key: &[u8], nonce: &[u8]) -> stream::EncryptorBE32<XChaCha20Poly1305> {
let aead = make_aead(key);
stream::EncryptorBE32::from_aead(aead, nonce.as_ref().into())
}
pub fn make_decryptor(key: &[u8], nonce: &[u8]) -> stream::DecryptorBE32<XChaCha20Poly1305> {
let aead = make_aead(key);
stream::DecryptorBE32::from_aead(aead, nonce.as_ref().into())
}
마무리
이렇게 직렬화를 할 때 데이터를 압축하고 암호화하는 방법을 알아보았다. 이번 프로젝트를 통해 현대적인 암호화 방법론에 대해 자세하게 공부할 수 있었다.
'IT > 러스트' 카테고리의 다른 글
| image_compressor 라이브러리 개선하기(3) (0) | 2024.03.04 |
|---|---|
| image_compressor 라이브러리 개선하기(2) - 테스트 개선하기 (0) | 2023.07.11 |
| image_compressor 라이브러리 개선하기(1) (0) | 2023.07.03 |
| 러스트로 tar 직접 구현하기 (1) (0) | 2022.12.14 |
| ImageCompressor2 개발기 (0) | 2022.03.24 |



