
Diary 프로젝트 일기 (5) - 부하테스트
발단
저번에 면접을 보면서 면접관이 이런 말을 했다.
"그래도 혹시 모르잖아요. 트래픽이 갑자기 몰릴 경우는 생각해보지 않으셨나요?"
소프트웨어 마에스트로 경험에 관한 질문이었다. 그때 우리는 각각 단일 인스턴스에 MySQL과 MongoDB를 올려 운영 서버에 사용하고 있었다. 당시에는 활성 사용자는 고사하고 가입자 수만 해도 손에 꼽을 만큼 적었기 때문에 싱글 인스턴스 DB가 아무런 문제가 없었다. 오히려 아무도 쓰지 않을 DB를 RDS 같은 곳에 올려두는 비용이 더 아까웠다.
우리라고 트래픽이 몰릴 걱정을 하지 않은 것은 아니었다. 다만 서비스 개발 자체가 훨씬 급한 업무였고 이에 트래픽 대비는 뒷전으로 밀렸을 뿐이었다. 심지어 초기 계획에는 서버에 대한 부하 테스트도 포함되어 있었다. 팀원 중 하나가 취업에 관심이 많았기 때문에 서비스 자체보다는 기술적인 학습에 더 관심이 많았기 때문이다. 이유가 어찌되었건 부하 테스트는 커녕 서비스 자체가 기간 막판에 가서야 출시되었고 가용성이나 성능을 올릴 시도는 하지 못했다.
그래서 이번에는 내 서비스 Diarity의 백엔드에 직접 부하 테스트를 해보기로 했다. 이런 시간 아니면 언제 해보겠나?
부하 테스트

나는 JMeter로 테스트를 했다. 먼저 내 기존 싱글 인스턴스 백엔드가 어느 정도부터 요청을 받지 못하는지 테스트해 보았다. 다음과 같은 설정일 때 응답이 매우 느려지기 시작했다.
다음은 그 결과이다.
상위 90퍼센트 이상의 응답속도가 3초 이상으로 매우 느렸을 뿐만 아니라 요청이 몰려드는 시간 동안 응답 속도가 급격하게 상승하는 것을 볼 수 있다.
APDEX는 생전 처음보는 0.091이 나왔다. 이러한 결과를 볼 때, 모든 요청이 불만족스러웠다고 볼 수 있다.
테스트 환경에 특별한 이상이 없다는 가정 아래에서, 이러한 결과의 이유로는 두 가지를 생각해볼 수 있다.
1 - 백엔드 인스턴스의 부족 가능성
현재 단일 인스턴스로 운영되고 있다보니 요청을 제때 처리하지 못할 가능성이 있다. 모든 연결마다 스레드를 생성했다면 총 1000개의 스레드가 필요할 것이고 단일 CPU에서 처리하기 버거웠을 것이다. 물론 스레드 풀을 사용해 스레드를 재사용했겠지만, 그럼에도 대기 큐에서 기다리다가 느려졌을 것이다.
2 - DB에서의 병목 가능성
데이터베이스 또한 단일 인스턴스로 운영되고 있다. 스프링 부트의 기본 HikaruCP의 최대 커넥션 개수는 10개이고, 설정으로 30개까지 늘린 상황이다. 이를 더 늘릴 수 있지만, MySQL의 최대 커넥션의 기본 설정은 151개다. DB 다중화 없이 백엔드 인스턴스만 너무 늘린다면 일부 커넥션들이 연결되지 못할 확률이 있다. DB의 사양을 스케일 업한 뒤, MySQL의 최대 커넥션을 늘릴 수 있을 것이다.
쿠버네티스 도입
먼저 첫 번째 가능성을 시험해보기로 했다. 이를 위해서는 백엔드 인스턴스의 다중화 작업이 필요하다. 그러나 문제가 있었다.
AWS 같은 IaaS에서가 아닌 Proxmox 홈서버에서 인스턴스 스케일 아웃은 매우 귀찮은 작업이다. Terraform 등으로 IaC를 구현할 수 있다고는 하지만 아직 거기까진 잘 아는 바가 없어서 제외했다. 그렇다면 내가 직접 손수 LXC 컨테이너들을 올리고 설정해야 할 뿐만 아니라, Jenkins가 그 모든 서버에 직접 접근해 배포해야 했다. 이는 각 컨테이너의 ip가 변할 수 없다는 의미이며 그 이후에 있을지도 모르는 또 다른 스케일 아웃 또한 수동으로 해야함을 의미한다.
이러한 이유로 여러 VM들 위에 쿠버네티스 클러스터를 올리기로 마음먹었다. 어차피 Harbor에 도커 이미지를 저장하여 이를 기반으로 배포하고 있었기에 충분히 가능하다고 생각했다. 물론 이번이 쿠버네티스를 처음 접하는 것이기 때문에 온갖 튜토리얼과 AI의 도움을 정말 많이 받았다.
다음은 대략적인 구조도이다.
온프로미스이므로 MetalLB를 사용했다. MetalLB는 로드밸런서 타입의 서비스가 생성되면, 외부 IP를 할당받아 해당 서비스에 연결한다. 그리고 그 서비스가 있는 노드를 연결해 리더로 선출한다. 스피커를 사용해 ip들을 다른 노드에 전달한다. 이제 들어온 트래픽은 해당 로드밸런서 타입의 서비스로 올바르게 전달되고 서비스는 자신들이 담당하는 파드에 트래픽을 라운드로빈으로 전달한다.
다음은 그렇게 만들어진 쿠버네티스 클러스터의 파드들이다.
이렇게 적어도 인스턴스 분산화 테스트를 위한 기본적인 k8s 클러스터 구성이 완료되었다. 이 설정은 테스트 이후 Helm 등을 사용해 실제 배포에도 활용할 예정이다.
실제로 효과가 있는가?
2개의 백엔드 인스턴스(파드)와 4개로 각각 실험해보았다. 먼저 2개인 경우다.
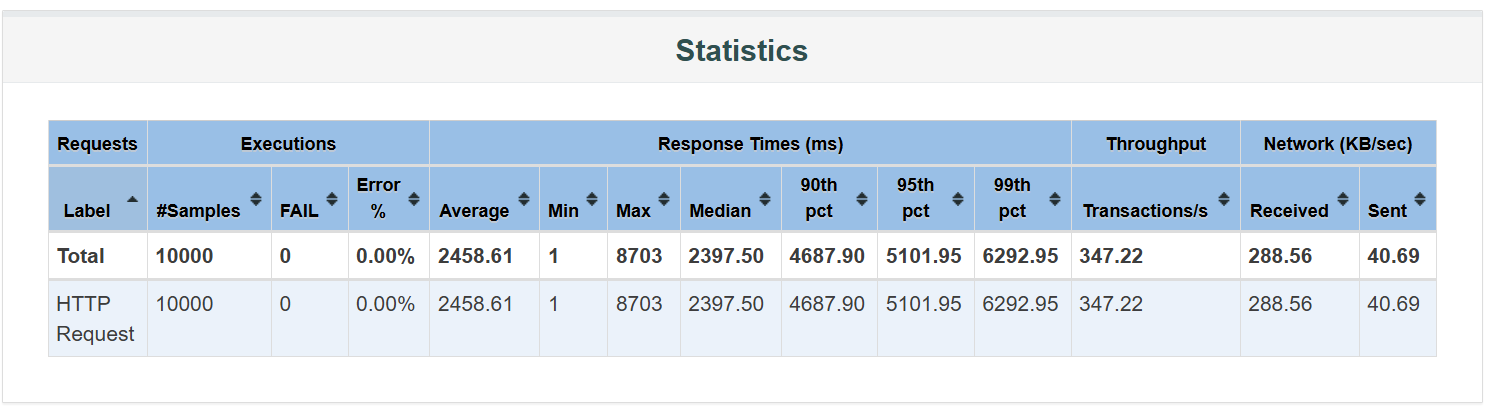

APDEX가 올라가긴 했지만 여전히 매우 부족하고, 실제 응답 시간 또한 감소하긴 했지만 여전히 느려보인다.
다음은 4개인 경우다.
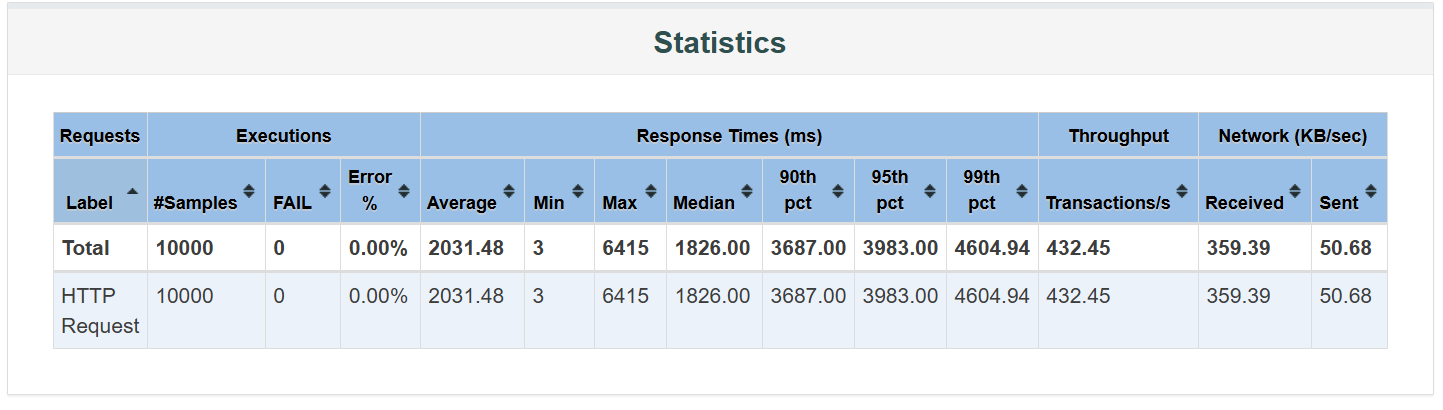
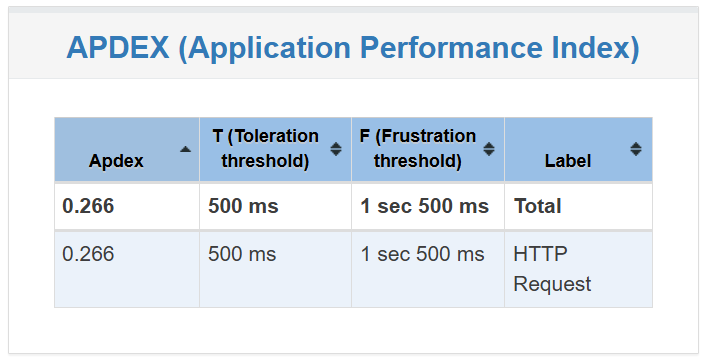
이 또한 APDEX가 약간 증가하고 응답 시간이 약간 줄어들 뿐 의미있는 차이가 있다고 보기 힘들었다.
그런데 놀라운 결과가 나타났다. 다음은 단일 인스턴스에서 커넥션 풀을 80개로 늘렸을 때의 결과다.

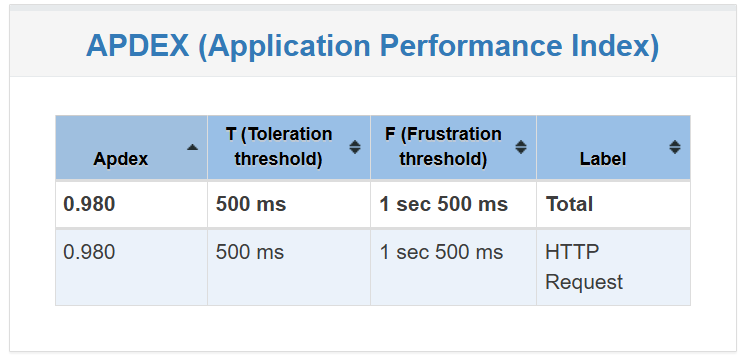
단일 인스턴스임에도 불구하고 응답속도가 현저히 상승했으며, APDEX 점수도 굉장히 많이 증가했다.
결론과 분석
- 백엔드 인스턴스의 다중화는 성능에 크게 의미있지 않았다. 이유는 다음과 같이 예측할 수 있다.
- 백엔드 로직이 복잡하지 않다. 테스트한 요청은 제일 많이 발생했던 단순한 조회 요청이고, 그 외에 복잡한 로직이 딱히 없다. CPU를 더 사용하는 로직이 추후 생긴다면 의미가 있을 수 있다.
- 그럼에도 각각 약간의 성능 향상이 있었는데, 이는 DB 커넥션 풀의 전체 사이즈가 더 커져서 그랬거나 각 스프링 인스턴스에서 응답을 분산 처리해 그랬을 가능성이 있다.
- 결국 DB가 병목이었다.
- 스프링은 충분히 효율적이었지만, DB 인스턴스의 스팩, 캐시의 부족, 특히 DB 커넥션들 간의 경쟁 등의 이유로 병목이 발생하였다.
- 한 DB에 여러 인스턴스가 동시에 연결하여 경쟁했을 가능성이 높다.
- 따라서 DB 다중화를 통한 읽기 요청 분산이 응답 속도에 있어서 더 효과적일 것이다.
- 스프링은 충분히 효율적이었지만, DB 인스턴스의 스팩, 캐시의 부족, 특히 DB 커넥션들 간의 경쟁 등의 이유로 병목이 발생하였다.
앞으로 할 일
면접관이 트래픽 이야기를 하면서 왜 백엔드 인스턴스 다중화가 아닌 DB 다중화만 물어봤을까 궁금했다. 그치만 실제 부하 테스트를 실시해보니 그 이유를 알겠다. 물론 CI/CD 관점에서 쿠버네티스와 Helm을 꼭 다루어보고 싶기도 하지만, 트래픽 관리 차원에서는 반드시 DB 다중화가 필요하다는 사실을 이번에 깨달았다.
앞으로는 일단 쿠버네티스와 Helm을 사용한 배포를 완성하려 한다. 그게 완료되면 MySQL DB의 다중화 작업에 착수할 것이고 다시 부하 테스트를 해보려 한다. 만약 그 이후에도 기회가 된다면 Redis 등을 사용한 캐싱 또한 테스트해보고 싶다.